۷ اردیبهشت ۱۴۰۰
2305 بازدید
مقالات تصادفی
- آموزش تغییر رنگ پس زمینه استوری اینستاگرام
- آموزش ویرایشگر ویدیویی رایگان OpenShot
- چگونه یک لیست سفارشی در اکسل بسازیم؟
- تلگرام به قابلیت برقراری تماس تصویری گروهی مجهز میشود
- ویپ (VoIP) چیست؟
- آموزش روشهای مختلف ماسک کردن در فتوشاپ
- ترافلاپس چیست و چه تفاوتی با ترابایت دارد؟
- آیا «جنسیس» در فیلم ترمیناتور همان گوگل است؟
- آموزش غیر فعال کردن تصحیح خودکار متن در اندروید
- دلایل محبوبیت وردپرس – بخش اول

در این مطلب به آموزش دیتابیس SQLite میپردازیم و در این مسیر کاربردها، مزایا و معایب آن را مورد بررسی قرار میدهیم. همچنین نحوه نصب آن را بیان خواهیم کرد و سپس یک پایگاه داده آزمایشی را نیز با آن ایجاد و مدیریت میکنیم تا به بهترین شکل ممکن با دیتابیس SQLite آشنا شویم.
SQLite چیست؟
SQLite یک سیستم مدیریت پایگاه داده رابطهای، Embeded و متن-باز است که در حدود سال 2000 طراحی شده است. SQLite یک دیتابیس سبک و بدون نیاز پیکربندی است که برای اجرا شدن به سرور و یا نصب نیاز ندارد. دیتابیس SQLite علیرغم سادگی خود، مجهز به قابلیتهای رایج بسیاری از سیستمهای مدیریت دیتابیس دیگر است.
خصوصیات کلیدی SQLite
در این بخش از آموزش دیتابیس SQLite به بررسی خصوصیات کلیدی این پایگاه داده میپردازیم.
- SQLite نسبت به سایر سیستمهای مدیریت پایگاه داده مانند SQL Server یا Oracle بسیار حجم کمتری دارد (حجم فایل آن از 500 کیلوبایت کمتر است).
- SQLite یک سیستم مدیریت پایگاه داده بر اساس رابطه کلاینت-سرور نیست، بلکه کتابخانه درون حافظهای است که میتوانید بدون نصب و پیکربندی مستقیماً آن را فراخوانی کرده و مورد استفاده قرار دهید.
- یک دیتابیس SQLite به طور معمول شامل یک فایل منفرد است که به همراه همه اجزای دیتابیس مانند جداول، نماها، تریگرها و غیره روی فضای دیسک رایانه شما ذخیره میشود. بدین ترتیب هیچ نیازی به وجود یک سرور اختصاصی وجود ندارد.
چه زمانی باید از SQLite استفاده کنیم؟
- اگر مشغول توسعه نرمافزار embedded برای دستگاههایی مانند تلویزیون، گوشیهای تلفن، دوربینها، دستگاههای الکترونیکی خانگی و غیره هستید، در این صورت SQLite گزینه مناسبی برای انتخاب محسوب میشود.
- SQLite میتواند حجم درخواستهای پایین تا متوسط HTTP را اداره کرده و اطلاعات پیچیده نشستها را برای یک وبسایت مدیریت کند.
- زمانی که نیاز باشد یک آرشیو از فایلها داشته باشیم، SQLite میتواند آرشیوها با اندازه کوچکتر و با متادیتای کمتر نسبت به آرشیوهای معمول ZIP تولید کند.
- اگر میخواهید برخی دادهها را درون یک اپلیکیشن پردازش کنید، میتوانید از SQLite به عنوان یک دیتاست موقت استفاده کنید. امکان بارگذاری دادهها در یک دیتابیس درون حافظهای SQLite و اجرای کوئریهای مورد نظر وجود دارد. همچنین میتوانید دادهها را در فرمتی که میخواهید در اپلیکیشن نمایش یابد از این دیتابیس استخراج کنید.
- SQLite یک روش آسان و کارآمد برای پردازش دادهها با استفاده از متغیرهای درون حافظهای در اختیار شما قرار میدهد. برای نمونه زمانی که مشغول توسعه برنامهای هستید که محاسباتی را روی برخی رکوردها اجرا میکند، میتوانید یک دیتابیس SQLite ایجاد کرده و رکوردها را در آن درج کنید و سپس تنها با یک کوئری رکوردها را انتخاب کرده و محاسبات مورد نظر خود را اجرا کنید.
- زمانی که به یک سیستم دیتابیس برای یادگیری و آموزش نیاز دارید، SQLite گزینه مناسبی محسوب میشود. چنان که پیشتر اشاره کردیم، این دیتابیس هیچ نیازی به نصب و پیکربندی ندارد. کافی است کتابخانه SQLite را روی رایانه خود کپی کنید تا شروع به یادگیری آن نمایید.
ضرورت آموزش دیتابیس SQLite چیست؟
در این بخش به ارائه برخی معیارها برای تعیین مواردی که میتوانید از SQLite در پروژههای خود استفاده کنید، میپردازیم.
- SQLite رایگان است. این دیتابیس به صورت متن-باز ارائه شده است و هیچ لایسنس تجاری برای کار با آن مورد نیاز نیست.
- SQLite یک سیستم مدیریت دیتابیس چند پلتفرمی است. میتوان از این سیستم روی طیف وسیعی از پلتفرمها مانند ویندوز، مک، لینوکس و یونیکس استفاده کرد. همچنین میتوان از SQLite روی انواع مختلفی از سیستمهای عامل embed-شده مانند Symbian و Windows CE استفاده کرد.
- SQLite یک روش مؤثر برای ذخیرهسازی دادهها ارائه میکند، چون در آن طول ستونها متغیر بوده و ثابت نیست. از این رو SQLite تنها فضایی که نیاز دارد را تخصیص میدهد. برای نمونه اگر یک ستون varchar(200) داشته باشید، و یک مقدار با طول 10 کاراکتر در آن قرار دهید، varchar(200) تنها فضای 20 کاراکتر را برای آن فیلد اختصاص میدهد و دیگر 200 کاراکتر اشغال نمیکند.
- طیف وسیعی از API-های SQLite وجود دارند. SQLite برخی API-ها برای انواع مختلفی از زبانهای برنامهنویسی ارائه میکند. از جمله این زبانها شامل زبانهای.NET مانند ویژوال بیسیک، سی شارپ، PHP، جاوا، آبجکتیو C، پایتون و بسیاری از زبانهای دیگر برنامهنویسی است.
- SQLite بسیار انعطافپذیر است.
- متغیرهای SQLite دارای نوعبندی دینامیک هستند، یعنی نوع متغیر تا زمانی که مقداری به آن انتساب نیافته است، مشخص نمیشود و در زمان اعلان تعریف نشده است.
- با استفاده از گزاره INSERT ON CONFLICT REPLACE میتوان به SQLite اعلام کرد که باید یک درج روی جدول انجام دهد و اگر ردیفهایی با کلیدهای اصلی یکسان بیابد، در این صورت باید آن مقادیر را با مقادیر درج شده بهروزرسانی کند.
- با استفاده از SQLite میتوانید همزمان و در یک نشست روی چندین دیتابیس کار کنید. کافی است این دیتابیسها را الحاق کنید تا به همه اجزای این دیتابیسها شامل جداول، نماها و غیره دسترسی داشته باشید.
محدودیتها و قابلیتهای ناموجود SQLite
در این بخش برخی قابلیتهایی که در SQLite پشتیبانی نمیشوند و همچنین محدودیتهای این سیستم مدیریت پایگاه داده را معرفی میکنیم.
- SQLite نه از الحاق RIGHT OUTER JOIN و نه از FULL OUTER JOIN پشتیبانی نمیکند. این دیتابیس تنها از الحاق LEFT OUTER JOIN پشتیبانی میکند.
- گزاره ALTER جدول محدودیتهایی دارد. در SQLite با استفاده از گزاره ALTER TABLE میتوانید تنها یک ستون اضافه کنید یا نام یک جدول را تغییر دهید. با این حال امکان انجام کارهای زیر وجود دارد.
- تغییر ( ALTER) ستون
- حذف (DROP) ستون
- افزودن (ADD) یک قید
- نماها (VIEWS) صرفا-خواندنی هستند. امکان نوشتن، درج یا بهروزرسانی نما وجود ندارد. با این حال میتوان یک نما را tigger کرد و سپس گزارههای INSERT ،DELETE یا UPDATE را روی آن اجرا نمود.
- دستورهای GRANT و REVOKE در SQLite پیادهسازی نشدهاند. تنها مجوزهای محدود دسترسی به فایل در SQLite پیادهسازی شدهاند. دلیل این امر آن است که SQLite برخلاف دیگر سیستمهای مدیریت دیتابیس، فایلهای دیسک را خوانده و مینویسد.
- SQL تنها از تریگرهای FOR EACH ROW پشتیبانی میکند و امکان استفاده از تریگرهای FOR EACH STATEMENT وجود ندارد.
دانلود و نصب SQLite
از اصلیترین مواردی که لازم است در آموزش دیتابیس SQLite به آن پرداخته شود، نحوه دانلود و نصب آن است. SQLite بسته به سیستم عامل شما بستههای نصب مختلفی را عرضه کرده است. همچنین این برنامه API-های گستردهای برای طیف متنوعی از زبانهای برنامهنویسی ارائه میکند. در این بخش از مقاله آموزش دیتابیس SQLite با روش دانلود و نصب نصاب پکیج این پایگاه داده آشنا شده و برخی پایگاههای داده ساده را بررسی میکنیم.
دانلود و نصب اینستالر پکیج SQLite
برای دانلود پکیجهای نصب در ویندوز 10 ابتدا باید به وبسایت رسمی دیتابیس SQLite مراجعه کرده و در بخش دانلودها، بستهای که با مشخصات ویندوز شما سازگار است را دانلود کنید.
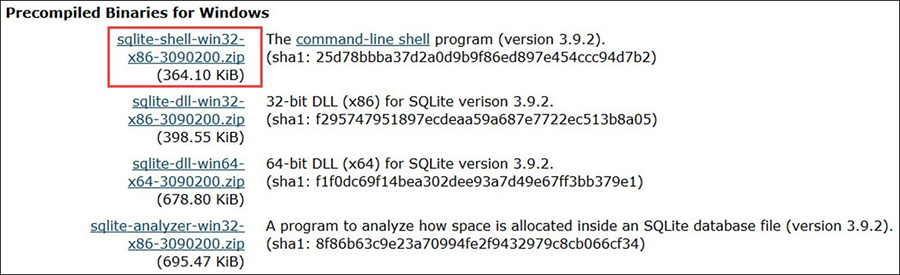
برنامه شل خط فرمان
پکیج دانلودی که در تصویر فوق هایلایت شده است، «برنامه خط فرمان» (CLP) نام دارد. CLP یک اپلیکیشن خط فرمان است که امکان دسترسی به سیستم مدیریت پایگاه داده SQLite و همه امکانات آن را فراهم میسازد. با استفاده از CLP میتوانید دیتابیس SQLite را ایجاد و مدیریت کنید. این همان ابزاری است که در سراسر این راهنما مورد استفاده قرار خواهیم داد و دو نسخه دارد:
- 32-bit DLL(x86) – کتابخانه اصلی سیستم دیتابیس SQLite برای پلتفرمهای X86.
- 64-bit DLL (x64) – کتابخانه اصلی سیستم دیتابیس SQLite برای پلتفرمهای X64.
نصب برنامه خط فرمان روی رایانه
در مراحلی که در ادامه توضیح میدهیم، با روش نصب برنامه خط فرمان (CLP) روی رایانه خود آشنا خواهید شد.
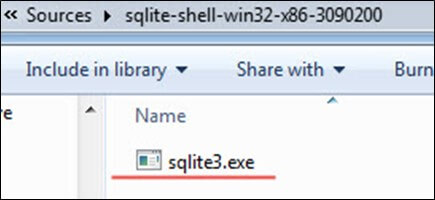
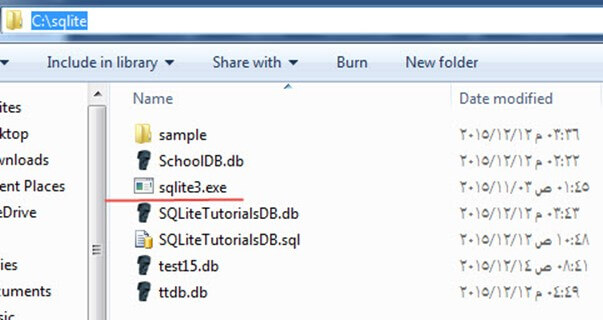
- گام 1: ابتدا پکیج دانلودی که در تصویر فوق مشخص شده است را روی سیستم خود دانلود کنید. این یک فایل فشرده zip است.
- گام 2: فایل zip فشرده را استخراج کنید. به این ترتیب مانند تصویر زیر با فایل sqlite3.exe مواجه خواهید شد.
- گام 3: نرمافزار My Computer را باز کرده و روی پارتیشن C دابل-کلیک کنید تا به این درایو بروید.
- گام 4: یک دایرکتوری جدید به نام sqlite ایجاد کنید.
- گام 5: فایل sqlite3.exe را در این درایو جدید بچسبانید. ما در سراسر این راهنما از این فایل برای اجرای کوئریهای خود استفاده خواهیم کرد.
البته برخی پکیجهای دیگر نیز برای مقاصد مختلف وجود دارند. روی ویندوز لزومی به استفاده از آنها وجود ندارد، اما ممکن است از سیستم عاملی به جز ویندوز استفاده کنید. در این صورت باید پکیجهای مربوط به سیستم عامل خودتان مانند لینوکس و یا Mac OS را مورد استفاده قرار دهید.
همچنین میتوانید در صورت تمایل، مستندات یا سورس کد این سیستم مدیریت دیتابیس را از وبسایت رسمی آن دانلود کنید. امکان دریافت API برای Windows Phone 8 یا .Net و دیگر زبانهای برنامهنویسی نیز وجود دارد. در ادامه این پکیجهای مختلف را به تفصیل توضیح دادهایم.
- سورس کد کامل این سیستم مدیریت دیتابیس را میتوانی از وبسایت رسمی SQLite دانلود کنید.
- در بخش documentation مستندات SQLite به صورت صفحههای HTML ارائه شده است. این همان مستندات آنلاین است که به صورتی عرضه شده است که قابل دانلود است.
- فایلهای باینری از پیش کامپایل شده برای لینوکس.
- فایلهای باینری از پیش کامپایل شده برای Mac OS X (به صورت X86).
- فایلهای باینری از پیش کامپایل شده برای Windows Phone 8 – در این مجموعه SDK و کامپوننتهایی برای ساحت یک اپلیکیشن ویندوز فون که از دیتابیس SQLite استفاده میکند عرضه شده است.
- فایلهای باینری از پیش کامپایل شده برای Windows Runtime – SDK و دیگر اجزا برای ساخت اپلیکیشنهایی برای اتصال دیتابیسهای SQLite به پلتفرمهای Windows Runtime.
- فایلهای باینری از پیش کامپایل شده برای NET. – برخی مجموعه فایلهای DLL و کتابخانههای NET. که میتوان از آنها در اپلیکیشنهای NET. برای اتصال به دیتابیسهای SQLite استفاده کرد.
SQLite Studio برای مدیریت دیتابیس SQLite
ابزارهای مدیریت زیادی برای دیتابیس SQLite ارائه شدهاند که موجب سهولت کار با این پایگاه داده میشوند. بدین ترتیب به جای ایجاد و مدیریت پایگاههای داده با استفاده از خط فرمان، از این ابزارها که یک رابط گرافیکی دارند برای ایجاد و اداره دیتابیسها استفاده میشود.
وبسایت رسمی SQLite Studio دهها ابزار این چنینی را فهرستبندی کرده است. یکی از این موارد SQLite Studio است. SQLite Studio یک ابزار پرتابل است که نیازی به نصب ندارد. این ابزار از نسخههای SQLite3 و SQLite2 پشتیبانی میکند. شما میتوانید به سهولت دادهها را به فرمتهای مختلفی مانند CSV ،HTML ،PDF و JSON خروجی بدهید. این ابزار متن-باز است و از یونیکد پشتیبانی میکند.
ایجاد یک دیتابیس SQLite نمونه
در این بخش به صورت گام به گام یک دیتابیس نمونه ایجاد خواهیم کرد و از آن در طول این آموزش دیتابیس SQLite استفاده میکنیم.
گام 1: یک فایل متنی را باز کرده و دستور زیر را در آن بنویسید:
CREATE TABLE [Departments] (
[DepartmentId] INTEGER NOT NULL PRIMARY KEY,
[DepartmentName] NVARCHAR(50) NULL
);
INSERT INTO Departments VALUES(1, 'IT');
INSERT INTO Departments VALUES(2, 'Physics');
INSERT INTO Departments VALUES(3, 'Arts');
INSERT INTO Departments VALUES(4, 'Math');
CREATE TABLE [Students] (
[StudentId] INTEGER PRIMARY KEY NOT NULL,
[StudentName] NVARCHAR(50) NOT NULL,
[DepartmentId] INTEGER NULL,
[DateOfBirth] DATE NULL,
FOREIGN KEY(DepartmentId) REFERENCES Departments(DepartmentId)
);
INSERT INTO Students VALUES(1, 'Michael', 1, '1998-10-12');
INSERT INTO Students VALUES(2, 'John', 1, '1998-10-12');
INSERT INTO Students VALUES(3, 'Jack', 1, '1998-10-12');
INSERT INTO Students VALUES(4, 'Sara', 2, '1998-10-12');
INSERT INTO Students VALUES(5, 'Sally', 2, '1998-10-12');
INSERT INTO Students VALUES(6, 'Jena', NULL, '1998-10-12');
INSERT INTO Students VALUES(7, 'Nancy', 2, '1998-10-12');
INSERT INTO Students VALUES(8, 'Adam', 3, '1998-10-12');
INSERT INTO Students VALUES(9, 'Stevens', 3, '1998-10-12');
INSERT INTO Students VALUES(10, 'George', NULL, '1998-10-12');
CREATE TABLE [Tests] (
[TestId] INTEGER NOT NULL PRIMARY KEY,
[TestName] NVARCHAR(50) NOT NULL,
[TestDate] DATE NULL
);
INSERT INTO [Tests] VALUES(1, 'Mid Term IT Exam', '2015-10-18');
INSERT INTO [Tests] VALUES(2, 'Mid Term Physics Exam', '2015-10-23');
INSERT INTO [Tests] VALUES(3, 'Mid Term Arts Exam', '2015-10-10');
INSERT INTO [Tests] VALUES(4, 'Mid Term Math Exam', '2015-10-15');
CREATE TABLE [Marks] (
[MarkId] INTEGER NOT NULL PRIMARY KEY,
[TestId] INTEGER NOT NULL,
[StudentId] INTEGER NOT NULL,
[Mark] INTEGER NULL,
FOREIGN KEY(StudentId) REFERENCES Students(StudentId),
FOREIGN KEY(TestId) REFERENCES Tests(TestId)
);
INSERT INTO Marks VALUES(1, 1, 1, 18);
INSERT INTO Marks VALUES(2, 1, 2, 20);
INSERT INTO Marks VALUES(3, 1, 3, 16);
INSERT INTO Marks VALUES(4, 2, 4, 19);
INSERT INTO Marks VALUES(5, 2, 5, 14);
INSERT INTO Marks VALUES(6, 2, 7, 20);
INSERT INTO Marks VALUES(7, 3, 8, 20);
INSERT INTO Marks VALUES(8, 3, 9, 20);گام 2: این فایل را با نام TutorialsSampleDB.sql در مسیر C:sqlite ذخیره کنید.
گام 3: ابزار خط فرمان ویندوز را از طریق منوی استارت و وارد کردن عبارت cmd باز کنید.
گام 4: با این کار مسیر پیشفرض در ابزار خط فرمان باز خواهد شد. باید با استفاده از وارد کردن دستور cd C:sqlite مسیر آن را پوشه C:sqlite که قبلاً ایجاد کردیم، عوض کنید.

گام 5: در این مرحله دستور زیر را بنویسید:
sqlite3 TutorialsSampleDB.db < TutorialsSampleDB.sqlدر صورتی که این دستور با موفقیت پایان یابد، همانند تصویر زیر هیچ خروجی پس از دستور دیده نخواهد شد:

گام 6: اکنون فایل پایگاه داده TutorialsSampleDB.db در دایرکتوری C:sqlite ایجاد شده است.
ایجاد، اجرا و تهیه نسخه پشتیبان از دیتابیس SQLite
دیتابیسهای SQLite بسیار سبک هستند و برخلاف دیگر سیستمهای پایگاه داده، نیاز به هیچ نوع نصب یا پیکربندی ندارند. تنها چیزی که در ابتدا به آن نیاز دارید، کتابخانه SQLite است که حجم آن کمتر از 500 کیلوبایت است.
در ادامه این مقاله آموزش دیتابیس SQLite با مباحث ایجاد پایگاه داده، دستور Open برای ایجاد دیتابیس در مکان خاص، ایجاد و مقداردهی جداول دیتابیس، پشتیبانگیری و حذف پایگاه داده آشنا خواهیم شد.
ساخت دیتابیس در SQLite
برخلاف سایر سیستمهای مدیریت پایگاه داده، در SQLite دستور CREATE DATABASE وجود ندارد. در ادامه به صورت گام به گام با روش ساخت یک پایگاه داده جدید در SQLite آشنا خواهیم شد.
از طریق منوی استارت و با تایپ عبارت cmd ابزار خط فرمان ویندوز را باز کنید. این ابزار پس از اجرا مسیر پیشفرض خود را نشان میدهد، که این مسیر روی کامپیوتری که ما مشغول کار با آن هستیم، به صورت C:UsersMGA است.
همان طور که در قسمت قبلی یعنی آموزش نصب دیتابیس SQLite عمل کردیم، شما اکنون باید یک پوشه AQLite در دایرکتوری C ایجاد کرده و فایل sqlite3.exe را در این پوشه کپی کرده باشید. اکنون با دستور زیر به جایی میرویم که sqlite3.exe در آن قرار دارد.
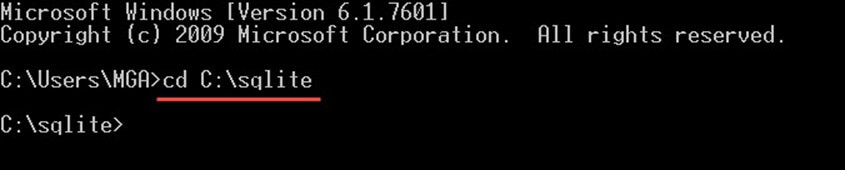
در ادامه ساختار مقدماتی دستور sqlite3 برای ایجاد یک پایگاه داده را مشاهده میکنید.
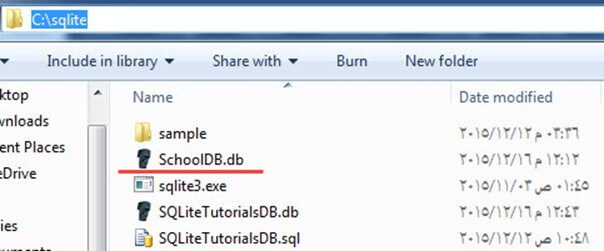
sqlite3 SchoolDB.dbاین دستور یک پایگاه داده جدید با نام SchoolDB.db در همان دایرکتوری که فایل با پسوند exe. را در آن کپی کردید، ایجاد خواهد کرد.

اگر به مسیر C:sqlite بروید میتوانید فایل SchoolDB.db را که مانند تصویر زیر ایجاد شده است، مشاهده کنید.
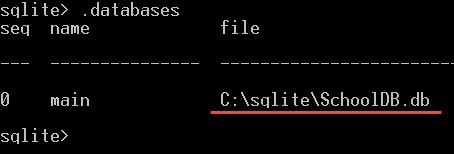
با نوشتن دستور زیر از ایجاد شدن پایگاه داده خود اطمینان حاصل کنید:
.databasesاین دستور لیستی از پایگاه دادههای ایجاد شده توسط دیتابیس SQLite را نشان میدهد و پایگاه داده جدید ما با عنوان SchoolDB.db باید در آنجا مشاهده شود.
ایجاد دیتابیس SQLite در یک مکان دلخواه و با دستور Open
اگر قصد دارید فایل پایگاه داده را در یک مکان خاص و نه در همان محلی که فایل sqlite3.exe در آن قرار دارد بسازید، میتوانید به شکل زیر عمل کنید. در مسیر C:sqlite به پوشهای بروید که فایل sqlite3.exe در آن قرار دارد.
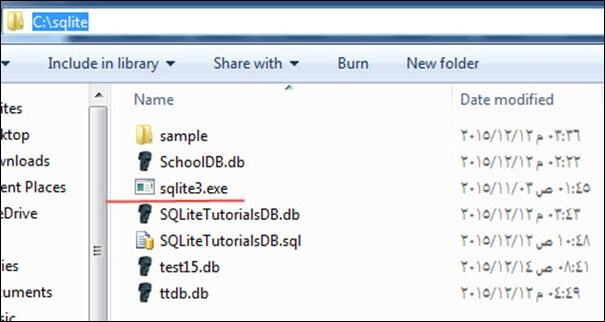
برای باز کردن ابزار خط فرمان دو بار روی sqlite3.exe کلیک کنید. پس از باز شدن آن، دستور زیر را اجرا کنید:
.open c:/users/mga/desktop/SchoolDB.dbبا این کار یک دیتابیس جدید با عنوان SchoolDB.db ایجاد شده و فایل پایگاه داده در محلی که مشخص کردهاید، ذخیره میشود. توجه کنید اگر دیتابیس از قبل ایجاد شده باشد، از همین دستور میتوانید برای باز کردن آن استفاده کنید. بنابراین اگر اینک یک بار دیگر دستور زیر را بنویسید، دیتابیس برای شما باز خواهد شد:
.open c:/users/mga/desktop/SchoolDB.dbبه این ترتیب SQLite بررسی میکند که فایلی با نام SchoolDB.db وجود دارد یا خیر. اگر چنین فایلی وجود داشته باشد، آن را باز کرده و در غیر این صورت، یک دیتابیس جدید با همان نام فایل مورد نظر در محل مشخص شده ایجاد میکند.
ایجاد دیتابیس و مقداردهی جداول از روی یک فایل
اگر یک فایل .SQL دارید که شامل شمای جداول است و میخواهید یک دیتابیس جدید با همان جداول داخل فایل بسازید، در مثال زیر روش این کار توضیح داده شده است.
ما در این مثال یک دیتابیس نمونه خواهیم ساخت. همچنین از این دیتابیس نمونه با نام SQLiteTutorialsDB در ادامه بخشهای این راهنما نیز استفاده میکنیم و آن را با جداولی مانند زیر مقداردهی میکنیم.
یک فایل متنی باز کرده و دستور زیر را در آن بنویسید:
CREATE TABLE [Departments] (
[DepartmentId] INTEGER NOT NULL PRIMARY KEY,
[DepartmentName] NVARCHAR(50) NOT NULL
);
CREATE TABLE [Students] (
[StudentId] INTEGER PRIMARY KEY NOT NULL,
[StudentName] NVARCHAR(50) NOT NULL,
[DepartmentId] INTEGER NULL,
[DateOfBirth] DATE NULL
);
CREATE TABLE [Subjects] (
[SubjectId] INTEGER NOT NULL PRIMARY KEY,
[SubjectName] NVARCHAR(50) NOT NULL
);
CREATE TABLE [Marks] (
[StudentId] INTEGER NOT NULL,
[SubjectId] INTEGER NOT NULL,
[Mark] INTEGER NULL
);کد فوق چهار جدول مانند زیر برای ما ایجاد میکند:
- جدول Departments دارای ستونهای زیر است:
- DepartmentId – یک عدد صحیح است که شناسه دپارتمان را نشان میدهد و به صورت «کلید اصلی» (PRIMARY KEY) اعلان شده است. در این خصوص در بخش قیدهای ستون بیشتر توضیح میدهیم.
- DepartmentName – یک نام رشتهای برای دپارتمان است و امکان داشتن مقدار تهی ندارد. این موضوع با تعیین قید NOT NULL مشخص شده است.
- جدول Students دارای ستونهای زیر است:
- StudentId یک عدد صحیح است و به صورت کلید اصلی اعلان شده است.
- StudentName نام دانشجو است و اجازه داشتن مقدار تهی را با قید NOT NULL لغو کرده است.
- DepartmentId یک عدد صحیح به شناسه دپارتمان در ستون مربوطه در جدول departments اشاره میکند.
- DateOfBirth – تاریخ تولد دانشجو است.
- جدول Subjects دارای ستونهای زیر است:
- SubjectId یک عدد صحیح است و به صورت PRIMARY KEY اعلان شده است.
- SubjectName – یک مقدار رشتهای و امکان داشتن مقادیر تهی را نمیدهد.
- جدول Marks دارای ستونهای زیر است:
- StudentId- یک عدد صحیح با شناسه دانشجو است.
- SubjectId – یک عدد صحیح با شناسه موضوع است.
- Mark – نمرهای که دانشجو در یک موضوع خاص کسب کرده و به صورت عدد صحیح تعیین شده است. همچنین امکان درج مقادیر تهی نیز وجود ندارد.
فایل را در SQLite به صورت SQLiteTutorialsDB.sql در همان مکانی که sqlite3.exe قرار دارد ذخیره کنید. برنامه cmd.exe را بازکرده و به آن دایرکتوری بروید که sqlite3.exe قرار دارد. دستور زیر ا در خط فرمان بنویسید:
sqlite3 SQLiteTutorialsDB.db < SQLiteTutorialsDB.sqlسپس یک دیتابیس جدید به نام SQLiteTutorialsDB ایجاد میشود و فایل SQLiteTutorialsDB.db مانند تصویر زیر در همان دایرکتوری قرار میگیرد:
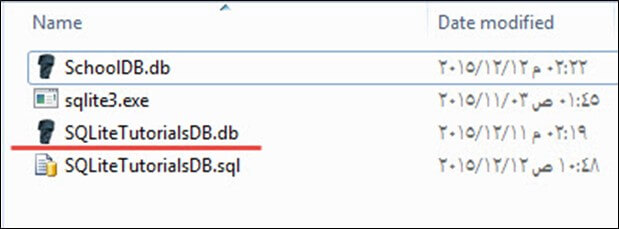
با دستور زیر میتوانید دیتابیسی که هم اینک ایجاد کردیم را باز کنید تا مطمئن شوید که به صورت صحیحی ایجاد شده است:
.open SQLiteTutorialsDB.dbسپس دستور زیر را وارد کنید:
.tablesاین دستور یک فهرست از جداول SQLiteTutorialsDB ارائه میکند و میتوانید جدولهایی که هماینک ایجاد کردیم را ببینید:

پشتیبانگیری از دیتابیس SQLite
برای پشتیبانگیری از یک دیتابیس SQLite، ابتدا باید آن را به طریقی که در زیر شرح میدهیم باز کنید. به پوشه C:sqlite رفته و روی فایل sqlite3.exe دابل-کلیک کنید تا باز شود. با استفاده از کوئری زیر پایگاه داده را باز کنید:
.open c:/sqlite/sample/SchoolDB.dbاین دستور دیتابیسی را باز خواهد کرد که در مسیر c:/sqlite/sample قرار دارد. اگر دیتابیس SQLite در همان مسیر قرار داشته باشد که فایل sqlite3.exe در آن قرار دارد، دیگر نیازی به تعیین مکان ندارید، به مثال زیر توجه کنید:
.open SchoolDB.dbسپس برای تهیه نسخه پشتیبان از یک دیتابیس، دستور زیر را بنویسید. با این کار یک نسخه پشتیبان کامل از دیتابیس در فایل جدید SchoolDB.db و در همان مسیر مشخصشده تهیه میشود:
.backup SchoolDB.dbاگر بعد از اجرای دستور فوق هیچ خطایی ظاهر نشد، به این معنی است که پشتیبانگیری شما از دیتابیس SQLite با موفقیت انجام شده است.
نکات مهم در زمان تهیه پشتیبان از دیتابیس SQLite
- امکان ساخت دو دیتابیس با نام یکسان در مکان یکسان وجود ندارد و نام دیتابیس در هر مکان باید یکتا باشد.
- نامهای دیتابیس به کوچکی و بزرگی حروف حساس هستند.
- برای ایجاد دیتابیسها به هیچ مجوزی نیاز ندارید.
به این ترتیب آموزش پشتیبانگیری از پایگاههای داده SQLite به پایان میرسد. در بخش بعدی به بررسی نمونهای عملی کار با دیتابیسهای SQLite میپردازیم.
بررسی مثالهایی از ایجاد، تغییر و حذف جداول دیتابیس SQLite
در این بخش از آموزش دیتابیس SQLite خواهیم دید که چطور در SQLite3 میتوانیم جداول جدید ایجاد کنیم و یا آنها را تغییر داده یا حذف کنیم.
ایجاد جدول در دیتابیس SQLite
در مثال زیر ساختار گزاره CREATE TABLE برای ایجاد یک جدول را مشاهده میکنید:
CREATE TABLE table_name(
column1 datatype,
column1 datatype
);برای ایجاد جدول، باید از کوئری CREATE TABLE به شکل زیر استفاده کنیم:
CREATE TABLE guru99 (
Id Int,
Name Varchar
);در بین دو براکت و بعد از نام جدول، تعداد ستونهای جدول را تعیین میکنیم. هر ستون باید دارای مشخصههای زیر باشد:
- یک نام که همان نام ستون است و باید در بین ستونهای قبلی نباشد.
- یک نوع داده که نوع داده مقادیر داخل ستون را تعیین میکند.
- همچنین برخی قیدها را میتوان برای ستون تعریف کرد که در بخشهای بعدی این راهنما در مورد آنها بیشتر صحبت خواهیم کرد.
حذف جدول در SQLite
برای حذف کردن جدول، از دستور DROP TABLE به شکل زیر و قبل از نام جدول استفاده میکنیم:
DROP TABLE guru99;
تغییر جدول در SQLite
با استفاده از دستور ALTER TABLE میتوانیم نام یک جدول را به شکل زیر تغییر دهیم:
ALTER TABLE guru99 RENAME TO guru100;برای تأیید این که نام جدول تغییر کرده است یا نه، میتوانید از دستور .tables جهت نمایش لیست جداول استفاده کنید. نام جدول شما باید اکنون به شکل زیر تغییر یافته باشد:
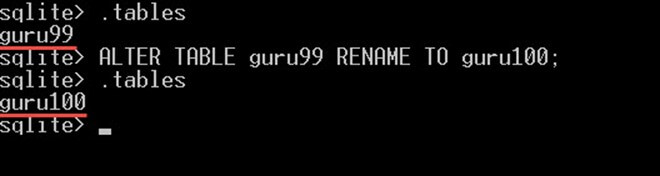
همان طور که میبینید نام جدول guru99 پس از دستور alter table به guru100 تغییر یافته است.
اضافه کردن ستون به جدول SQLite
با استفاده از دستور ALTER TABLE مانند مثال زیر میتوانید به تعداد ستونها اضافه کنید:
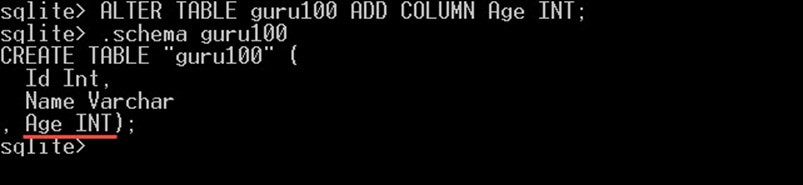
ALTER TABLE guru100 ADD COLUMN Age INT;با این کار جدول guru100 تغییر یافته و یک ستون جدید Age به آن اضافه میشود. اگر هیچ خروجی مشاهده نکردید، به این معنی است که گزاره مورد نظر با موفقیت اجرا و ستون اضافه شده است. عدم وجود خروجی به این معنی است که کرسر پس از sqlite> قرار گرفته و مانند تصویر زیر هیچ متنی پس از آن وجود ندارد:

با این حال، برای تأیید این که ستون اضافه شده است، میتوانیم از دستور .schema guru100 استفاده کنیم که تعریف جدول را به دست میدهد و میتوانید ببینید که ستون جدید عملاً اضافه شده است:
وارد کردن مقدار در جدول SQLite
برای وارد کردن مقادیر در یک جدول دیتابیس SQLite، از گزاره INSERT INTO به صورت زیر استفاده میکنیم:
INSERT INTO Tablename(colname1, colname2, ….) VALUES(valu1, value2, ….);همچنین میتوانید نام ستونها را بعد از نام جدول حذف کرده و مانند مثال زیر عمل کنید:
INSERT INTO Tablename VALUES(value1, value2, ….);در چنین حالتی، در صورت حذف نام ستونها از جداول، تعداد مقادیر درج شده باید برابر با همان تعداد ستونهای جدول باشد. سپس هر مقدار در ستون مربوط به خود وارد میشود. به عنوان مثال:
INSERT INTO guru100 VALUES(1, 'Mike', 25);نتیجه دستور بالا به صورت زیر خواهد بود:
- مقدار ۱ در ستون id وارد خواهد شد.
- مقدار Mike در ستون Name وارد خواهد شد.
- مقدار ۲۵ در ستون Age وارد خواهد شد.

گزاره INSERT … DEFAULT VALUES
امکان مقداردهی جداول با برخی مقادیر پیشفرض به صورت زیر نیز وجود دارد:
INSERT INTO Tablename DEFAULT VALUES;اگر ستونی امکان درج مقدار تهی یا پیشفرض را نداشته باشد، با اجرای دستور فوق با خطای NOT NULL constraint failed مانند تصویر زیر مواجه خواهید شد:

Primary Key و Foreign Key در SQLite
قیود یک ستون با این هدف تعریف شدهاند که قوانین ورود دادهها به یک ستون و نوع دادههایی که مجاز هستند را معین کنند تا از این طریق دادهها پیش از ورود به آن ستون اعتبارسنجی شوند. قیود ستونها در زمان ایجاد جدول در تعریف ستون ذکر میشوند.
Primary Key در SQLite
تمام مقادیر موجود در ستون Primary Key باید یکتا بوده و تهی نباشند. Primary Key را میتوان فقط در یک ستون یا روی ترکیبی از ستونها اعمال کرد. در حالت «ترکیبی از ستونها» مقادیر باید برای تمامی ردیفهای جدول منحصر به فرد باشند. روشهای مختلفی برای تعریف «کلید اصلی» (Primary Key) روی یک جدول وجود دارد که در ادامه برخی از آنها را بررسی میکنیم.
- در تعریف خود ستون:
ColumnName INTEGER NOT NULL PRIMARY KEY;- به صورت تعریف جداگانه:
PRIMARY KEY(ColumnName);- برای ایجاد ترکیبی از ستونها به صورت Primary Key:
PRIMARY KEY(ColumnName1, ColumnName2);قید تهی نبودن (Not null)
قید تهی نبودن دیتابیس SQLite مانع از ایجاد ستونی با مقادیر تهی میشود:
ColumnName INTEGER NOT NULL;
قید پیشفرض (DEFAULT)
اگر هیچ مقداری را در یک ستون وارد نکنید، قید Default خود به خود مقدار پیشفرضی را در جدول درج میکند. به مثال زیر توجه کنید:
ColumnName INTEGER DEFAULT 0;
قید یکتایی (UNIQUE) در SQLite
این قید باعث میشود در بین مقادیر یک ستون، مقدار تکراری وجود نداشته باشد. به مثال زیر توجه کنید:
EmployeeId INTEGER NOT NULL UNIQUE;دستور بالا باعث میشود مقادیر ستون «شناسه کارمندان» (EmployeeId) همگی منحصر به فرد باشند و مقداری تکراری وارد آن نشود. توجه کنید که این وضعیت تنها روی مقادیر ستون EmployeeId اعمال میشود.
قید CHECK در SQLite
این قید دیتابیس SQLite بر مبنای یک شرط، مقادیر را پیش از ورود به جدول کنترل کرده و در صورت عدم مطابقت با شرط به آنها اجازه درج در جدول را نمیدهد. به مثال زیر توجه کنید:
Quantity INTEGER NOT NULL CHECK(Quantity > 10);با این شرط شما نمیتوانید مقداری کمتر از 10 را در ستون Quantity وارد کنید.
کلید خارجی یا Foreign KEY در SQLite چیست؟
کلید خارجی در SQLite قیدی است که وجود یک مقدار موجود در جدول را در جدول دیگری که با جدول نخست رابطه دارد و کلید خارجی در آن تعریف شده است، تأیید میکند.
در حین کار با چندین جدول، وقتی دو جدول وجود دارد که با هم رابطه و یک ستون مشترک دارند، اگر قصد دارید اطمینان حاصل کنید که مقدار درج شده در یکی از آنها باید در ستون جدول دیگر نیز وجود داشته باشد، باید از قید foreign key در ستون مشترک استفاده کنید.
در این حالت هنگامی که میخواهید مقداری را در آن ستون وارد کنید، این محدودیت اطمینان حاصل میکند که مقدار درج شده در ستون جدول مرتبط وجود دارد یا خیر. توجه داشته باشید که قید foreign key به طور پیشفرض در SQLite فعال نیست و شما باید در ابتدا با اجرای دستور زیر آن را فعال کنید:
PRAGMA foreign_keys = ON;قیود کلید خارجی از نسخه 3.6.10 در SQLite معرفی شدهاند. در ادامه یک مثال را در همین زمینه مورد بررسی قرار میدهیم.
مثالی از کلید خارجی
فرض کنید دو جدول به نامهای Students و Departments داریم. جدول Students فهرستی از دانشجویان دارد و جدول departments نیز فهرستی از دپارتمانها را نمایش میدهد. هر دانشجو به یک دپارتمان تعلق دارد، یعنی هر دانشجو دارای یک ستون دپارتمان است.
اکنون به بررسی شیوه مفید بودن کلید خارجی برای اطمینان یافتن از این که مقدار شناسه دپارتمان در جدول دانشجویان باید در جدول دپارتمانها نیز موجود باشد، میپردازیم.
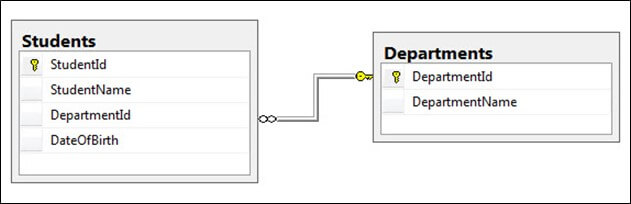
بنابراین اگر یک کلید خارجی روی فیلد DepartmentId در جدول Students ایجاد کرده باشیم، هر مقدار departmentId درج شده در این جدول باید در جدول Departments نیز موجود باشد.
CREATE TABLE [Departments] (
[DepartmentId] INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
[DepartmentName] NVARCHAR(50) NULL
);
CREATE TABLE [Students] (
[StudentId] INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
[StudentName] NVARCHAR(50) NULL,
[DepartmentId] INTEGER NOT NULL,
[DateOfBirth] DATE NULL,
FOREIGN KEY(DepartmentId) REFERENCES Departments(DepartmentId)
);برای بررسی این که قیود خارجی چطور از درج مقادیر یا عناصر تعریف نشده در جدولی که با جدول دیگر رابطه دارد جلوگیری میکنند، به بررسی یک مثال میپردازیم. در این مثال جدول Departments یک قید کلید خارجی روی جدول Students دارد، بنابراین هر مقدار دپارتمان که در جدول departmentId درج شود، باید در جدول departments نیز حضور داشته باشد. اگر تلاش کنیم یک مقدار departmentId که در جدول departments وجود ندارد را درج کنیم، قید کلید خارجی ما را از انجام این کار باز خواهد داشت.
در ادامه دو دپارتمان IT و Arts را در جدول departments به صورت زیر درج میکنیم:
INSERT INTO Departments VALUES(1, 'IT');
INSERT INTO Departments VALUES(2, 'Arts');این دو گزاره باید دو دپارتمان را در جدول departments درج کنند، با اجرای کوئری SELECT * FROM Departments پس از دستور فوق میتوانید مطمئن شوید که این دو مقدار درج شدهاند.
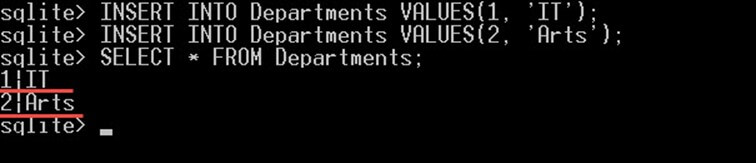
سپس تلاش کنید تا یک دانشجوی جدید را با یک departmentId که در جدول departments وجود ندارد درج کنید:
INSERT INTO Students(StudentName,DepartmentId) VALUES('John', 5);این ردیف درج نمیشود و با خطای FOREIGN KEY constraint failed مواجه خواهیم شد.
انواع داده (Data Types) در SQLite
انواع دادهها در دیتابیس SQLite در مقایسه با سایر سیستمهای مدیریت پایگاه داده متفاوت است. در SQLite، میتوانید انواع دادهها را به طور معمول اعلان کرده و همچنین قادر هستید تا هر مقدار را در هر نوع داده ذخیره کنید.
SQLite انواع کمی دارد. در واقع هیچ نوع دادهای وجود ندارد و میتوانید هر نوع دادهای را که میخواهید در هر ستونی ذخیره کنید. این وضعیت، نوعبندی دینامیک نام دارد. در نوعبندی استاتیک، مانند سایر سیستمهای مدیریت پایگاه داده، اگر ستونی با نوع داده عدد صحیح اعلان شده باشد، فقط میتوانید مقادیر عدد صحیح را در آن وارد کنید. اما در انواع دینامیک مانند SQLite، نوع ستون با مقدار درج شده تعیین شده و SQLite بسته به نوع آن، این مقدار را ذخیره میکند.
کلاسهای ذخیرهسازی SQLite
در دیتابیس SQLite بسته به نوع مقادیر، روشهای مختلف ذخیرهسازی وجود دارد. این روشهای مختلف ذخیرهسازی در SQLite کلاسهای ذخیرهسازی نامیده میشوند. کلاسهای ذخیرهسازی در SQLite به شکل زیر هستند:
- NULL – این کلاس ذخیرهسازی برای ذخیره هر مقدار تهی (NULL) مورد استفاده قرار میگیرد.
- INTEGER – هر مقدار عددی به صورت یک مقدار صحیح علامتدار ذخیره میشود. این نوع داده میتواند هر دو نوع عدد صحیح مثبت و منفی را در خود نگهداری کند. مقادیر INTEGER در SQLite بسته به مقدار عدد در 1، 2، 3، 4، 6 یا 8 بایت ذخیره میشوند.
- REAL – این کلاس ذخیرهسازی برای ذخیره مقادیر اعشاری استفاده میشود و اعداد را در فضای 8 بایتی ذخیره میکند.
- TEXT – رشتههای متنی را نگهداری میکند. این نوع همچنین از انکودینگهای مختلفی مانند UTF-8 ،UTF-16 BE یا UTF-26LE پشتیبانی میکند.
- BLOB – از این نوع داده برای ذخیرهسازی فایلهای بزرگ مانند تصاویر یا فایلهای متنی استفاده میکنیم. مقادیر این نوع داده در یک آرایه مانند مقدار ورودی ذخیره میشوند.
نوع Affinity در SQLite
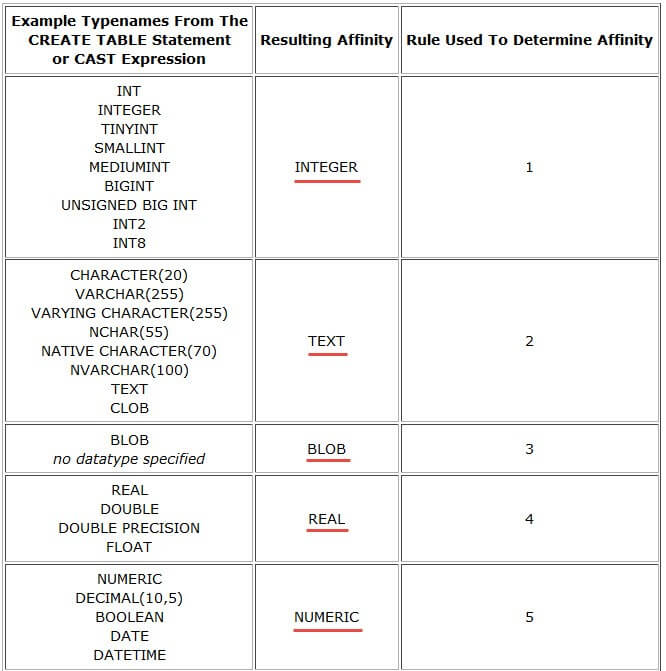
نوع Affinity، در اصل نوع مناسب برای دادههای ذخیره شده در یک ستون است. با این وجود، میتوان هر نوع داده را به دلخواه در این ستون ذخیره کرد. توجه کنید که این نوع پیشنهادی است و الزامی برای استفاده از آن وجود ندارد. این انواع با هدف سازگاری بیشتر SQLite با دیگر سیستمهای مدیریت پایگاه داده معرفی و به کار بسته شدهاند. هر ستون تعریف شده در یک دیتابیس SQLite بر حسب دادههای آن دارای یک نوع Affinity نیز هست. برخی از انواع Affinity در دیتابیس SQLite به صورت زیر هستند:
- .TEXT
- .NUMERIC
- .INTEGER
- .REAL
- .BLOB
روش تعیین affinity از روی نوع داده اعلان شده به صورت زیر است:
- Affinity نوع INTEGER در صورتی انتساب مییابد که نوع اعلان شده شامل رشته INT باشد.
- Affinity نوع TEXT در صورتی انتساب مییابد که نوع داده ستون شامل یکی از رشتههای TEXT یا CHAR یا CLOB باشد. برای نمونه نوع VARCHAR موجب انتساب پیوستگی از نوع Text میشود.
- Affinity از نوع BLOB در صورتی انتساب مییابد که هیچ نوعی برای ستون اعلان نشده باشد و یا نوع داده به صورت BLOB باشد.
- Affinity از نوع REAL زمانی انتساب مییابد که نوع ستون شامل یکی از رشتههای DOUB ،REAL یا FLOAT باشد.
- Affinity از نوع NUMERIC برای نوع داده دیگر انتساب مییابد.
همچنین یک جدول در همان صفحه وجود دارد که برخی مثالها را برای نگاشت بین انواع داده SQLite و affinitiy -های آنها بر اساس قواعد زیر نمایش میدهد.
مثالهایی از مرتبسازی انواع داده در SQLite
در این بخش به بررسی برخی نمونههای مرتبسازی انواع دادهها میپردازیم.
مرتبسازی عدد با integer
هر ستون از نوع دادهای که شامل کلمه INT باشد، affinity از نوع INTEGER را دریافت میکند. این ستون در کلاس ذخیرهسازی INTEGER مرتبسازی میشود. همه انواع دادههای زیر یک affinity از نوع INTEGER دریافت میکنند.
- INT, INTEGER, BIGINT.
- INT2, INT4, INT8.
- TINYINT, SMALLINT, MEDIUM INT.
Affinity از نوع INTEGER در SQLite میتواند عدد صحیح انتسابیافته (مثبت یا منفی) را از 1 بایت تا بیشینه 8 بایت نگهداری کند.
مرتبسازی اعداد با REAL در SQLite
اعداد REAL اعدادی با دقت اعشاری دو برابر هستند. SQLite اعداد REAL را به صورت آرایههای 8 بایتی ذخیره میسازد. در ادامه فهرستی از انواع داده در SQLite میبینید که میتوانید برای ذخیرهسازی اعداد REAL مورد استفاده قرار دهید:
- REAL.
- DOUBLE.
- DOUBLE PRECISION.
- FLOAT.
مرتبسازی دادههای بزرگ با BLOB
برای ذخیرهسازی فایلهای بزرگ در یک دیتابیس SQLite تنها یک روش وجود دارد و آن استفاده از نوع داده BLOB است. این نوع داده برای ذخیرهسازی فایلهای بزرگ مانند تصاویر، فایلها (از هر نوع) و غیره مورد استفاده قرار میگیرد. این فایل به صورت آرایه بایتی تبدیل میشود و سپس در همان اندازه فایل ورودی ذخیره میشود.
مرتبسازی مقادیر بولی در SQLite
SQLite یک کلاس ذخیرهسازی مجزا برای مقادیر بولی ندارد. با این حال مقادیر BOOLEAN به صورت Integer-هایی با مقدار 0 برای وضعیت نادرست و مقدار برای وضعیت درست ذخیره میشوند.
مرتبسازی تاریخ و زمان در SQLite
امکان اعلان تاریخ و یا زمان در SQLite با استفاده از یکی از انواع داده زیر وجود دارد:
- DATE
- DATETIME
- TIMESTAMP
- TIME
توجه کنید که هیچ کلاس ذخیرهسازی مجزا برای ذخیره DATE یا DATETIME در SQLite وجود ندارد. به جای آن هر مقدار که با یکی از انواع داده قبلی اعلان شده است، بسته به فرمت داده مقادیر درج شده به صورت زیر روی یک کلاس ذخیرهسازی نگهداری میشود:
- TEXT – اگر مقدار تاریخ در فرمت ISO8601 با استفاده از قالببندی YYYY-MM-DD HH:MM:SS.SSS وارد شده باشد، به این صورت ذخیره میشود.
- REAL – اگر مقدار تاریخ به صورت تعداد روز ژولین یعنی روزهایی که از ظهر گرینویچ در تاریخ 24 نوامبر 4714 پیش از میلاد سپری شده است، وارد شود، در این صورت مقدار تاریخ به صورت REAL ذخیره میشود.
- INTEGER – برای ذخیره زمان به صورت زمان یونیکس یعنی تعداد ثانیههای سپری شده از تاریخ 1970-01-01 00:00:00 UTC مورد استفاده قرار میگیرد.
جمعبندی انواع داده در SQLite
SQLite از طیف متنوعی از انواع داده پشتیبانی میکند. اما همزمان بسته به نوع دادهها بسیار انعطافپذیر است. شما میتوانید هر نوع مقدار را در هر نوع دادهای قرار دهید. SQLite مفاهیم جدیدی را نیز در انواع داده وارد کرده است که affinity نوع و کلاس ذخیرهسازی از جمله آنها هستند و از این نظر با دیگر سیستمهای مدیریت پایگاه داده تفاوت دارد.
کوئریهای SQLite
برای نوشتن کوئریهای SQL در یک دیتابیس SQLite، باید بدانید که بندهای SELECT ،FROM ،WHERE ،GROUP BY ،ORDER BY و LIMIT چگونه کار میکنند و چطور باید از آنها استفاده کنید. در این بخش از راهنمای آموزش دیتابیس SQLite با روش استفاده از این بندها (Claues) و شیوه نوشتن بندهای SQLite آشنا خواهید شد.
خواندن دادهها با Select
بند SELECT گزاره اصلی برای جستجوی یک پایگاه داده SQLite است. با استفاده از این بند بیان میکنید که میخواهید چه چیزی انتخاب شود. اما قبل از آن به بند FROM نگاهی میاندازیم که با استفاده از آن میتوان دادهها را انتخاب کرد.
بند FROM برای مشخص کردن مکانهایی که میخواهید دادهها را انتخاب کنید، استفاده میشود. در بخشی از این بند میتوانید یک یا چند جدول یا کوئریهای فرعی را برای انتخاب داده از آن مشخص کنید. توجه کنید که در مثالهای زیر باید sqlite3.exe را اجرا کرده و به صورت زیر یک اتصال با دیتابیس نمونه برقرار سازید.
ابتدا MY Computer را باز کرده و به دایرکتوری C:sqlite بروید. سپس فایل sqlite3.exe را باز کنید.
با دستور زیر دیتابیس TutorialsSampleDB.db را باز کنید:
اکنون آماده هستید که هر نوع کوئری را روی دیتابیس اجرا نمایید.
در بند SELECT میتوانید نه تنها یک نام ستون بلکه بسیاری چیزهای دیگر را نیز برای انتخاب شدن تعیین کنید. به مثالهای زیر توجه کنید.
* SELECT
این دستور همه ستونها را از جداول ارجاع یافته (یا کوئریهای فرعی) در بند FROM انتخاب میکند. به مثال زیر توجه کنید:
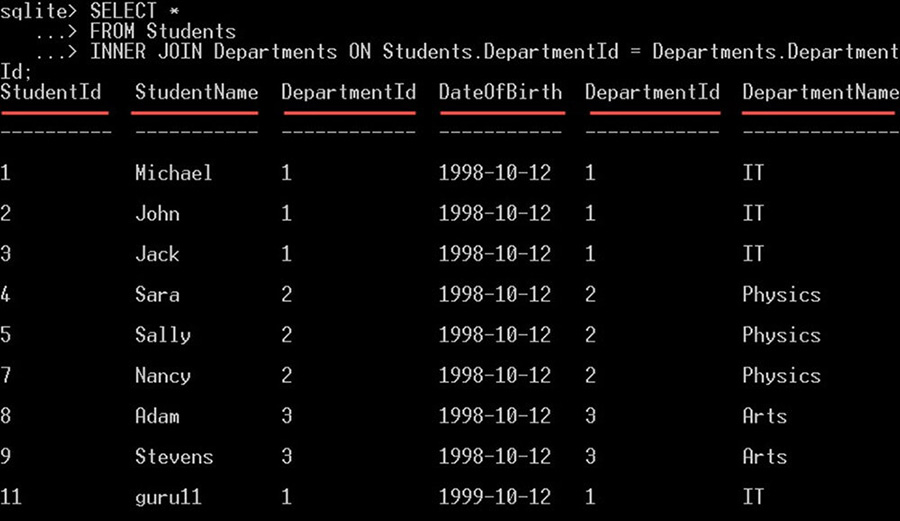
SELECT *
FROM Students
INNER JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;این دستور همه ستونها را از هر دو جدول students و departments انتخاب میکند.
*.SELECT tablename
این دستور همه ستونها را از تنها جدول tablename انتخاب میکند. به مثال زیر توجه کنید:
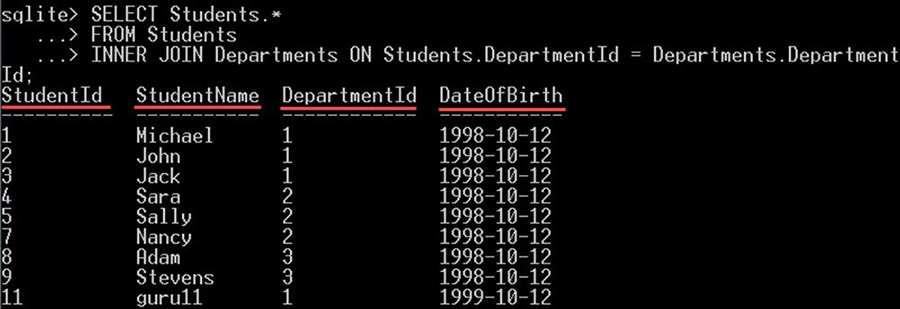
SELECT Students.*
FROM Students
INNER JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;با اجرای دستور فوق، همه ستونها صرفاً از جدول students انتخاب میشوند:
یک مقدار لفظی
منظور از «مقدار لفظی» (literal value) یک مقدار ثابت است که میتواند در گزاره SELECT مورد استفاده قرار گیرد. امکان استفاده از مقادیر لفظی به صورت معمول به همان روشی برای انتخاب نام ستونها در بند SELECT وجود دارد. این مقادیر لفظی برای هر ردیف از ردیفهای بازگشتی از کوئری SQL نمایش مییابند.
در ادامه برخی نمونههای مقادیر مختلف لفظی که میتوان انتخاب کرد را میبینید:
- لفظ عددی – اعداد در هر فرمت مانند 1، 2.55 و غیره.
- لفظهای رشتهای – هر نوع رشته مانند IRAN یا this is a sample text و غیره.
- NULL – هر مقدار تهی.
- Current_TIME – زمان جاری را به دست میدهد.
- CURRENT_DATE – تاریخ جاری را به دست میدهد.
این مقادیر لفظی در برخی موقعیتها که برای یک مقدار ثابت را برای همه ردیفهای بازگشتی انتخاب کنید بسیار مفید هستند. برای نمونه اگر بخواهید همه دانشجویان را از جدول Students با یک ستون جدید به نام country که شامل مقدار USA است، انتخاب کنید، میتوانید به صورت زیر عمل کنید:
SELECT *, 'USA' AS Country FROM Students;بدین ترتیب همه ستونهای students به علاوه ستون Country به صورت زیر به دست میآید:
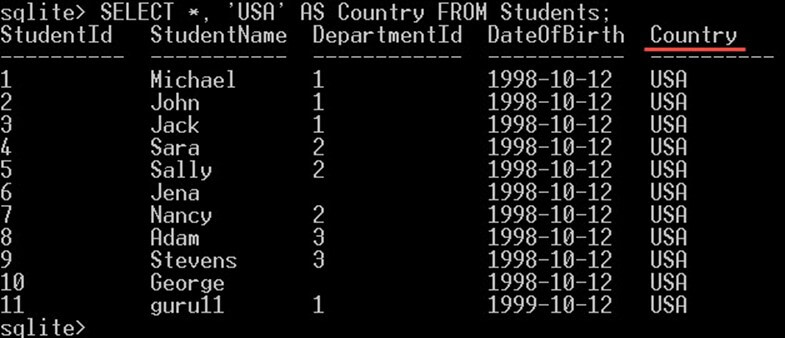
توجه کنید که این ستون جدید Country در عمل یک ستون جدید که به جدول اضافه شده باشد نیست. این یک ستون مجازی است که در کوئری برای نمایش نتایج ایجاد شده است و ربطی به جدول ندارد.
نامها و اسامی مستعار
اسم مستعار (alias) یک نام جدید است که به ستونها داده میشود و امکان انتخاب ستونها را با نامی جدید فراهم میسازد. اسامی مستعار ستونها با استفاده از کلیدواژه AS تعیین میشوند.
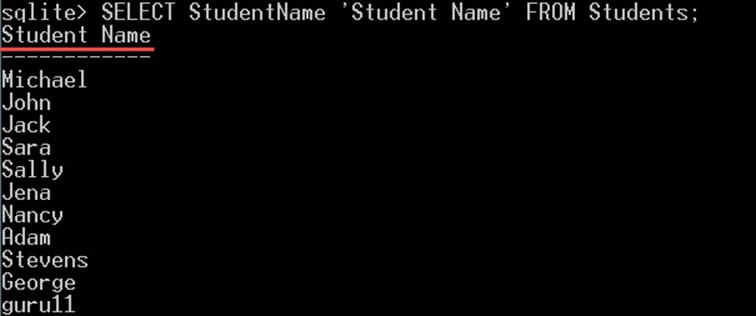
برای نمونه اگر بخواهید ستون StudentName را انتخاب کنید تا با نام Student Name به جای عنوان StudentName بازگشت یابد، میتواند از اسم مستعار به صورت زیر استفاده کنید:
SELECT StudentName AS 'Student Name' FROM Students;بدین ترتیب ستون نامهای دانشجویان به جای StudentName با نام Student Name به صورت زیر بازگشت مییابد:
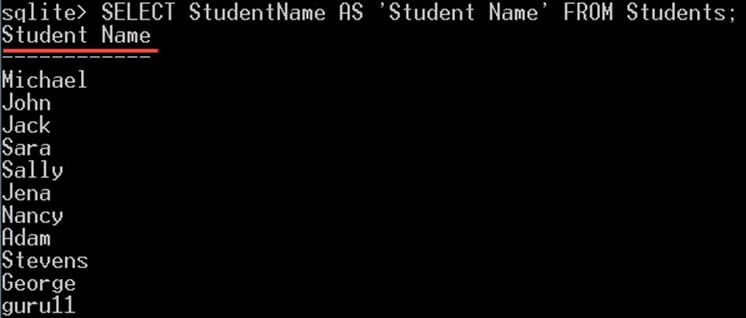
توجه کنید که نام ستون همچنان StudentName است. ستون StudentName در جدول به همان قرار قبلی است و هیچ چیزی از سوی اسم مستعار تغییر نمییابد. در واقع اسم مستعار نام ستون را تغییر نمیدهد، بلکه نام نمایشی را در بند SELECT عوض میکند.
همچنین توجه کنید که کلیدواژه AS اختیاری است و میتوانید مانند مثال زیر اسم مستعار را بدون آن نیز درج کنید:
SELECT StudentName 'Student Name' FROM Students;دستور فوق دقیقاً همان خروجی کوئری قبلی را به دست میدهد:
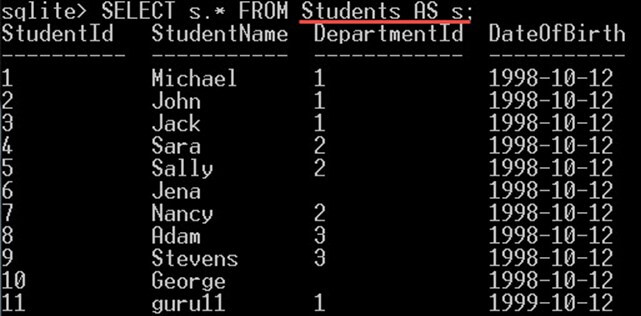
شما میتوانید با استفاده از همان کلیدواژه AS نه تنها برای ستونها بلکه برای جداول نیز اسم مستعار تعیین کنید. به مثال زیر توجه کنید:
SELECT s.* FROM Students AS s;دستور فوق همه ستونهای موجود در جدول Students را در اختیار شما قرار میدهد:
این وضعیت در صورتی که بخواهید بیش از یک جدول را به هم الحاق کنید بسیار مفید خواهد بود. بدین ترتیب به جای تکرار کردن نام کامل در کوئری، میتوانید یک نام مستعار کوتاه به هر جدول بدهید. به کوئری نمونه زیر توجه کنید:
SELECT Students.StudentName, Departments.DepartmentName
FROM Students
INNER JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;این کوئری هر نام دانشجو را از جدول Students به همراه نام دپارتمان مربوطه از جدول Departments انتخاب میکند.
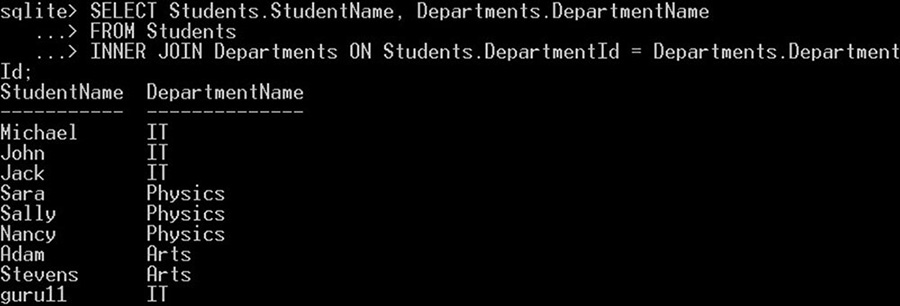
با این حال، میتوان کوئری را میتوان به صورت زیر نیز نوشت:
SELECT s.StudentName, d.DepartmentName
FROM Students AS s
INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
- ما نام مستعار s را برای جدول Students و نام مستعار d را برای جدول departments انتخاب کردهایم.
- سپس به جای استفاده از نام کامل جدول، از اسامی مستعار آنها برای ارجاع به این جداول استفاده میکنیم.
- INNER JOIN دو یا چند جدول را با استفاده از یک شرط به هم الحاق میکند. در این مثال، ما جدول Students را با جدول Departments با ستون DepartmentId ملحق میکنیم.
دستور فوق خروجی زیر را به دست میدهد:
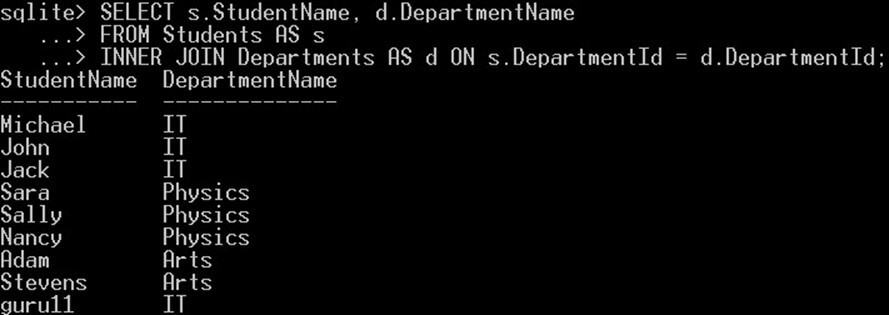
کوئری WHERE
همان طور که در بالا دیدیم، نوشتن کوئریهای SQL از طریق بند SELECT تنها با استفاده از بند FROM، تمام ردیفهای موجود در جداول را برای شما نمایش خواهد داد. اما اگر میخواهید دادههای برگشتی را فیلتر کنید، باید بند WHERE را به دستور خود اضافه کنید. بند WHERE برای فیلتر کردن نتیجهای که توسط کوئری SQL پرسیده شده است، استفاده میشود. طرز کار بند WHERE به صورت زیر است:
- در بند WHERE میتوانید یک «عبارت» (Expression) را تعیین کنید.
- این عبارت برای هر ردیف بازگشتی از جدول (ها) که در بند FROM مشخص شده است، اعتبارسنجی میشود.
- این عبارت به صورت یک عبارت بولی ارزیابی خواهد شد و تنها میتواند صحیح، ناصحیح و یا NULL باشد.
- تنها ردیفهایی که عبارتشان به صوت TRUE ارزیابی شده باشد بازگشت خواهند یافت و آنهایی که FALSE هستند یا نتایج NULL دارند نادیده گرفته میشوند و در مجموعه نتایج قرار نمیگیرند.
- برای فیلتر کردن نتایج با استفاده بند WHERE باید از عبارتها و عملگرها استفاده کنید.
لیست عملگرها در SQLite و شیوه استفاده از آنها
در این بخش به بررسی شیوه استفاده از عبارتها و عملگرها برای فیلتر کردن نتایج یک کوئری میپردازیم. «عبارت» (Expression)، یک یا چند مقدار لفظی یا ستون است که با استفاده از عملگر با هم ترکیب شدهاند. توجه کنید که میتوانید از عبارتها هم در بند SELECT و هم در بند WHERE استفاده کنید.
در مثالهایی که در ادامه میآیند، تلاش خواهیم کرد تا عبارتها و عملگرها را در هر دو بند SELECT و بند WHERE بررسی کنیم تا با روش استفاده از آنها آشنا شوید. انواع مختلفی از عبارتها و عملگرها وجود دارند که میتوان به صورت زیر مورد استفاده قرار داد.
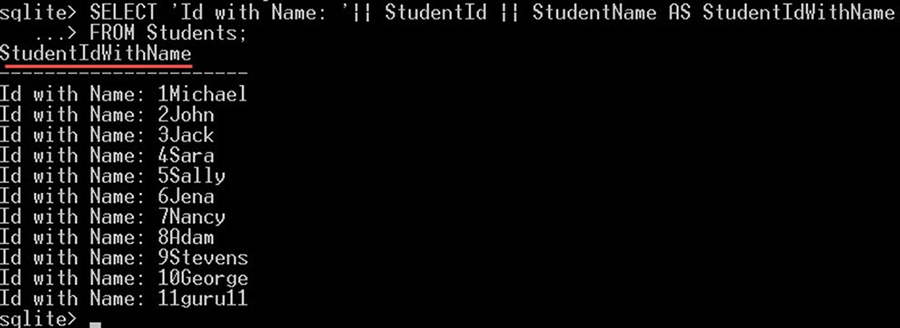
عملگر concatenation (||) در SQLite
این عملگر برای الحاق یک یا چند مقدار لفظی یا ستون به همدیگر مورد استفاده قرار میگیرد. این عملگر یک رشته از نتایج همه مقادیر لفظی یا ستونها به هم اتصال یافته تولید میکند. به مثال زیر توجه کنید:
SELECT 'Id with Name: '|| StudentId || StudentName AS StudentIdWithName
FROM Students;دستور فوق به صورت یک اسم مستعار جدید StudentIdWithName درمیآید:
رشته لفظی با مقدار Id with Name: با مقدار ستون StudentId و مقدار ستون StudentName الحاق مییابد.
عملگر CAST در SQLite
عملگر CAST برای تبدیل یک مقدار از یک نوع داده به نوع داده دیگر استفاده میشود.
برای نمونه اگر یک مقدار عددی به صورت یک رشته مانند 12.5 ذخیره شده باشد و بخواهید آن را به یک مقدار عددی تبدیل کنید، میتوانید از عملگر CAST به این منظور به صورت زیر استفاده کنید:
CAST('12.5' AS REAL)همچنین در صورتی که یک مقدار اعشاری مانند 12.5 داشته باشید و بخواهید تنها بخش صحیح آن را به دست آورید، میتوانید آن را به نوع INTEGER به صورت زیر تبدیل کنید:
CAST(12.5 AS INTEGER)مثال
در دستور زیر تلاش میکنیم مقادیر مختلف را به انواع داده متفاوت تبدیل کنیم:
SELECT CAST('12.5' AS REAL) ToReal, CAST(12.5 AS INTEGER) AS ToInteger;به این ترتیب نتیجه زیر حاصل میشود:

نتیجه به صورت زیر است:
- CAST(‘12.5’ AS REAL) – مقدار ‘12.5’ یک مقدار رشتهای است و به نوع REAL تبدیل میشود.
- CAST(12.5 AS INTEGER) – مقدار 12.5 یک عدد اعشاری است و به یک عدد صحیح تبدیل میشود، یعنی بخش اعشاری حذف شده و عدد 12 به دست میآید.
عملگرهای حسابی SQLite
با استفاده از عملگرهای حسابی میتوان یک یا چند مقدار لفظی یا ستونهای عددی را انتخاب کرده و یک مقدار عددی بازگشت داد. عملگرهای حسابی SQLite به صورت زیر هستند:
- جمع (+) – مجموع دو عملوند را به دست میدهد.
- تفریق (-) – دو عملوند را از هم کم کرده و تفاضل را بازگشت میدهد.
- ضرب (*) – حاصلضرب دو عملوند را بازگشت میدهد.
- باقیمانده (modulo) – با علامت % – باقیمانده تقسیم دو عملوند را به دست میدهد.
- تقسیم (/) – خارجقسمت تقسیم عملوند چپ بر عملوند راست را به دست میدهد.
مثال
در مثال زیر تلاش میکنیم پنج عملگر حسابی را با مقادیر عددی لفظی یکسان بررسی کنیم.
بند SELECT
SELECT 25+6, 25-6, 25*6, 25%6, 25/6;دستور فوق نتیجه زیر را ارائه میکند:

به شیوه استفاده از گزاره SELECT بدون بند FROM توجه کنید. این کار تا زمانی که مقادیر لفظی را انتخاب میکنیم در SQLite مجاز است.
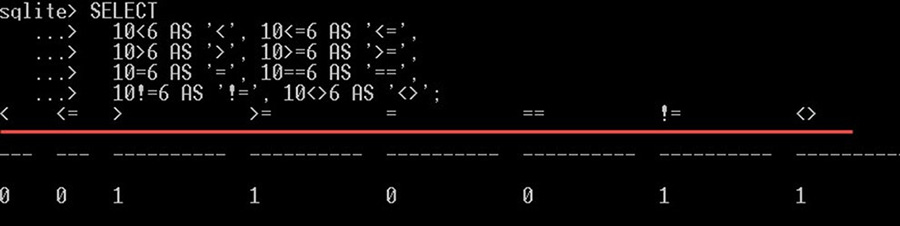
عملگرهای مقایسه SQLite
دو عملوند را با همدیگر مقایسه کرده و مانند مثال زیر یک مقدار درست یا نادرست بازگشت میدهیم:
- “<” – در صورتی که عملوند چپ کمتر از عملوند راست باشد، مقدار TRUE بازگشت میدهد.
- “<=” – در صورتی که عملوند چپ کمتر یا مساوی عملوند راست باشد، مقدار TRUE بازگشت میدهد.
- “>” – در صورتی که عملوند چپ بزرگتر از عملوند راست باشد، مقدار TRUE بازگشت میدهد.
- “>=” – در صورتی که عملوند چپ بزرگتر یا مساوی عملوند راست باشد، مقدار TRUE بازگشت میدهد.
- “=” و”==” – در صورتی که دو عملوند چپ و راست برابر باشند، مقدار TRUE بازگشت میدهد. توجه کنید که هر دو عملگر یکسان هستند و هیچ اختلافی ندارند.
- “!=” و “<>” – در صورتی که دو عملوند چپ و راست برابر نباشند، مقدار TRUE بازگشت میدهد. توجه کنید که هر دو عملگر یکسان هستند و هیچ اختلافی ندارند.
دقت کنید که SQLite مقدار true را با 1 نمایش میدهد و مقدار false نیز با 0 نمایش پیدا میکند.
مثال
SELECT
106 AS '<', 10<=6 AS '<=',
10>6 AS '>', 10>=6 AS '>=',
10=6 AS '=', 10==6 AS '==',
10!=6 AS '!=', 10<>6 AS '<>';دستور فوق نتیجه زیر را ایجاد میکند:
عملگرهای تطبیق الگو در SQLite
در این بخش عملگرهایی را که برای «تطبیق الگو» (Pattern Matching) در SQLite استفاده میشود، بررسی میکنیم.
LIKE – این عملگر برای تطبیق الگو مورد استفاده قرار میگیرد. با استفاده از LIKE میتوانید به دنبال مقادیری که با یک الگوی مشخص تطبیق پیدا میکنند با استفاده از یک wildcard بگردید.
عملوند سمت چپ میتواند یک مقدار رشته لفظی یا یک ستون رشتهای باشد. این الگو میتواند به صورت زیر بیان شود:
- الگوی شمول – برای نمونه StudentName LIKE ‘%a%’. این دستور به دنبال نامهای دانشجویانی میگردد که شامل حرف a در هر موقعیتی در ستون StudentName باشند.
- الگوهای آغازین – برای نمونه StudentName LIKE ‘a%’. این الگو به دنبال نامهای دانشجویانی میگردد که با حرف a آغاز شده باشند.
- الگوهای پایانی – برای نمونه StudentName LIKE ‘%a’. این الگو به دنبال نامهای دانشجویانی میگردد که با حرف a خاتمه یافته باشند.
- الگوی تطبیق کاراکتر منفرد – برای این که هر کاراکتر منفردی در یک رشته تطبیق پیدا کند از عملگر زیرخط (_) استفاده میکنیم. برای نمونه StudentName LIKE ‘J___’. این الگو به دنبال نامهای دانشجویانی با طول 4 کاراکتر میگردد. این الگو باید با حرف J آغاز شود و میتواند هر سه کاراکتر دیگر را پس از حرف J داشته باشد.
مثالهای تطبیق الگو
نامهای دانشجویانی که با حرف j آغاز میشوند:
SELECT StudentName FROM Students WHERE StudentName LIKE 'j%';نتیجه به صورت زیر است:

نامهای دانشجویان که با حرف y پایان مییابد:
SELECT StudentName FROM Students WHERE StudentName LIKE '%y';نتیجه به صورت زیر است:

نامهای دانشجویانی که شامل حرف n باشند:
SELECT StudentName FROM Students WHERE StudentName LIKE '%n%';نتیجه به صورت زیر است:

GLOB – معادل عملگر LIKE است، اما GLOB برخلاف LIKE به کوچکی/بزگی حروف حساس است. برای نمونه دو دستور زیر نتایج متفاوتی بازگشت میدهند:
SELECT 'Jack' GLOB 'j%';
SELECT 'Jack' LIKE 'j%';دستور فوق نتیجه زیر را به دست میدهد:
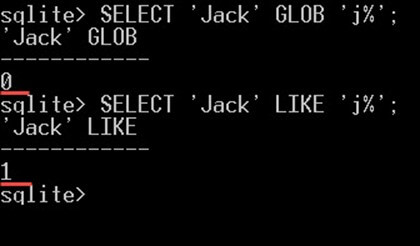
گزاره نخست مقدار 0 (false) بازگشت میدهند، زیرا عملگر GLOB به کوچکی/بزرگی حروف حساس است. از این رو j برابر با J نیست. با این حال، گزاره دوم مقدار 1 (true) باز میگرداند، زیرا عملگر LIKE به کوچکی/بزرگی حروف حساس است. از این رو j معادل J است.
عملگرهای دیگر دیتابیس SQLite
در این بخش برخی عملگرهای دیگر سیستم مدیریت پایگاه داده SQLite را بررسی میکنیم.
AND در SQLite
این یک عملگر منطقی است که یک یا چند عبارت را ترکیب میکند. این عملگر تنها در صورتی مقدار true بازگشت میدهد که همه عبارتها مقدار true تولید کنند. با این حال، تنها در صورتی مقدار false بازگشت میدهد که همه عبارتها مقدار false داشته باشند.
مثال
کوئری زیر به دنبال دانشجویانی میگردد که در آنها شرط StudentId > 5 برقرار بوده و StudentId > 5 با حرف N آغاز شود. نامهای دانشجویان که بازگشت مییابند، باید هر دوی این شرطها را داشته باشند:
SELECT *
FROM Students
WHERE (StudentId > 5) AND (StudentName LIKE 'N%');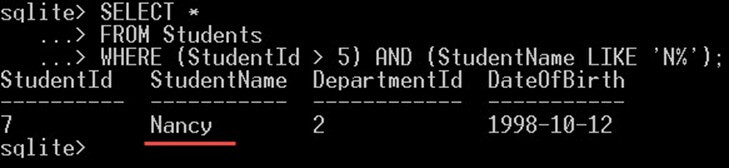
چنان که از تصویر خروجی فوق مشخص است، این دستور تنها نتیجه Nancy را بازگشت میدهد. Nancy تنها دانشجویی است که هر دو شرط مورد نظر ما را دارد.
OR در SQLite
یک عملگر منطقی است که یک یا چند عبارت را ترکیب میکند، به طوری که اگر یکی از عملگرها مقدار true به دست بدهد، در این صورت مقدار این عملگر true خواهد بود. با این حال اگر همه عبارتها false باشند، نتیجه نهایی نیز false خواهد بود.
مثال
کوئری زیر به دنبال دانشجویانی میگردد که شرط StudentId > 5 را داشته باشند و یا StudentName با حرف N آغاز شود. اسامی دانشجویان بازگشتی باید دستکم یکی از این شروط را داشته باشند:
SELECT *
FROM Students
WHERE (StudentId > 5) OR (StudentName LIKE 'N%');دستور فوق نتیجه زیر را به دست میدهد:
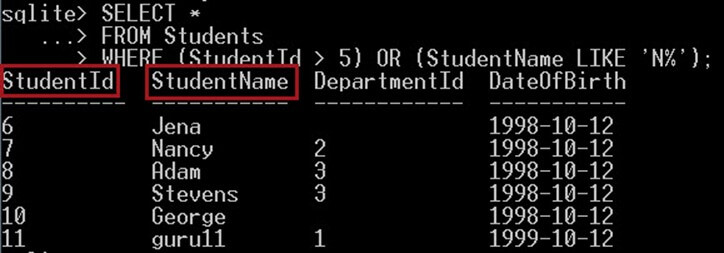
همچنان که در تصویر خروجی فوق مشاهده میکنید، نام دانشجویانی که با حرف N آغاز میشود و همچنین شناسه آنها بزرگتر از 5 است ارائه شده است.
همچنان که میبینید این نتیجه از مثال قبلی که با عملگر AND اجرا شده بود متفاوت است.
BETWEEN در SQLite
BETWEEN برای انتخاب مقادیری که درون فاصله بین دو مقدار قرار دارند مورد استفاده قرار میگیرد. برای نمونه X BETWEEN Y AND Z در صورتی مقدار true (1) بازگشت میدهد که X بین دو مقدار Y و Z قرار داشته باشد. در غیر این صورت مقدار false (0) بازگشت مییابد. X BETWEEN Y AND Z معادل X >= Y AND X <= Z است، یعنی X باید بزرگتر یا مساوی Y و همچنین X کمتر یا مساوی Z باشد.
مثال
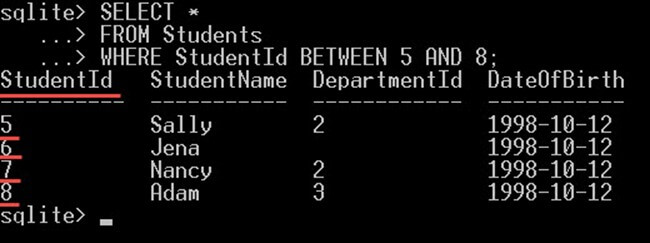
در کوئری مثال زیر یک کوئری برای دریافت دانشجویانی که عدد شناسهشان بین 5 و 8 است مینویسیم:
SELECT *
FROM Students
WHERE StudentId BETWEEN 5 AND 8;کوئری فوق تنها دانشجویانی که مقدار شناسهشان برابر با 5، 6، 7 و 8 است بازگشت میدهد:
IN در SQLite
این عملگر یک عملوند و یک لیست از عملوندها را برمیدارد و در صورتی که مقدار عملوند اول برابر با یکی از مقادیر عملوندهای موجود در لیست باشد مقدار true بازگشت میدهد. عملگر IN در صورتی مقدار true (1) بازگشت میدهد که لیست عملوندها شامل مقدار عملوند اول باشد. در غیر این صورت مقدار (false (0 بازگشت خواهد یافت. برای نمونه col IN(x, y, z) معادل کوئری (col=x) or (col=y) or (col=z) است.
مثال
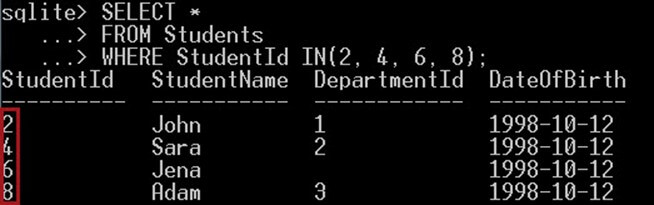
کوئری زیر دانشجویانی را انتخاب میکند که شناسهشان تنها برابر با 2، 4، 6 و 8 باشد:
SELECT *
FRM Students
WHERE StudentId IN(2, 4, 6, 8);نتیجه به صورت زیر است:
کوئری پیشین دقیقاً نتیجهای مانند کوئری زیر به دست میدهد، زیرا معادل هم هستند:
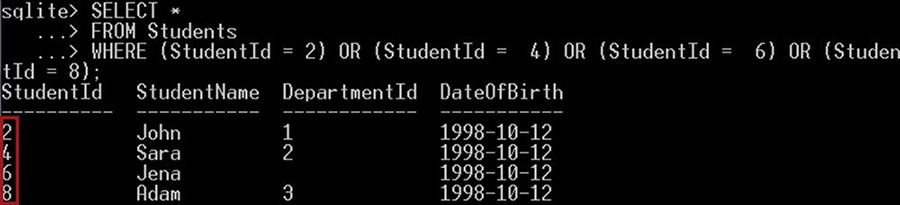
SELECT *
FROM Students
WHERE (StudentId = 2) OR (StudentId = 4) OR (StudentId = 6) OR (StudentId = 8);هر دو کوئری، خروجی دقیقاً یکسانی ارائه میکنند. با این حال این دو کوئری اختلافی با هم دارند. در کوئری قبلی از عملگر IN استفاده کردیم، اما در کوئری دوم از چند عملگر OR بهره گرفتیم.
عملگر IN معادل استفاده از چند عملگر OR است. از این رو کوئری زیر:
WHERE StudentId IN(2, 4, 6, 8)معادل کوئری زیر است:
WHERE (StudentId = 2) OR (StudentId = 4) OR (StudentId = 6) OR (StudentId = 8);نتیجه به صورت زیر است:
NOT IN در SQLite
عملگر NOT IN متضاد IN است، اما ساختار مشابهی دارد. این عملگر یک عملوند و یک لیست از عملوندها میگیرد. این عملگر در صوتی مقدار true بازگشت میدهد که مقدار عملوند اول برابر با یکی از مقادیر عملوندهای لیست ارسالی نباشد. یعنی در صورتی مقدار true (0) به دست میآید که لیست شامل عملوند مورد نظر نباشد:
NOT IN(x, y, z)کوئری فوق معادل کوئری زیر است:
(col<>x) AND (col<>y) AND (col<>z)مثال
کوئری زیر دانشجویانی را انتخاب میکند که شناسهشان برابر با یکی از اعداد 2, 4, 6 یا 8 باشد:
SELECT *
FROM Students
WHERE StudentId NOT IN(2, 4, 6, 8);نتیجه به صورت زیر است:
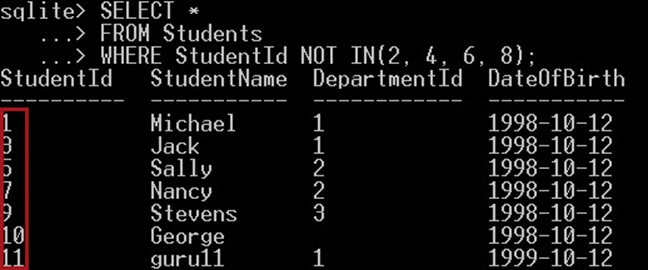
کوئری قبلی نتیجهای دقیقاً برابر با کوئری زیر به دست میدهد، زیرا معادل هم هستند:
SELECT *
FROM Students
WHERE (StudentId <> 2) AND (StudentId <> 4) AND (StudentId <> 6) AND (StudentId <> 8);خروجی به صورت زیر است:
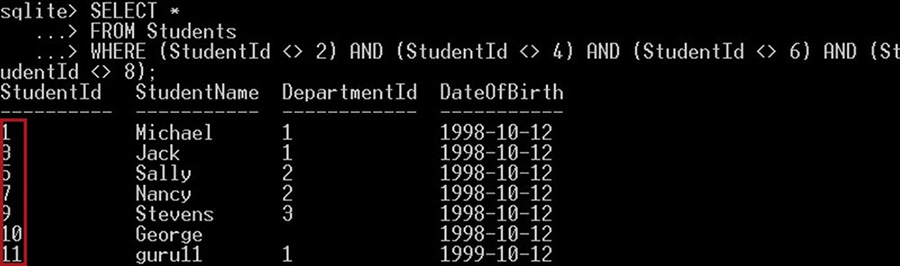
در تصویر فوق میبینیم که از چند عملگر عدم برابری به صورت <> استفاده کردهایم تا لیست دانشجویان را به دست آوریم که شناسهشان برابر با یکی از اعداد 2، 4، 6 یا 8 نباشد. این کوئری همه دانشجوهایی که شناسهشان اعدادی به جز موارد فوق است را بازگشت میدهد.
EXISTS در SQLite
عملگرهای EXISTS هیچ عملوندی نمیگیرند. این عملگر تنها یک بند SELECT پس از خود دارد. عملگر EXISTS در صورتی مقدار true (1) بازگشت میدهد که ردیفی از سوی بند SELECT بازگشت یافته باشد. در صورتی که هیچ ردیفی بازگشت نیابد، مقدار false (0) بازگشت خواهد یافت.
مثال
در مثال زیر، نام دپارتمان را در صورتی انتخاب میکنیم که شناسه دپارتمان در جدول دانشجویان موجود باشد:
SELECT DepartmentName
FROM Departments AS d
WHERE EXISTS (SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId);کوئری فوق نتیجه زیر را به دست میدهد:
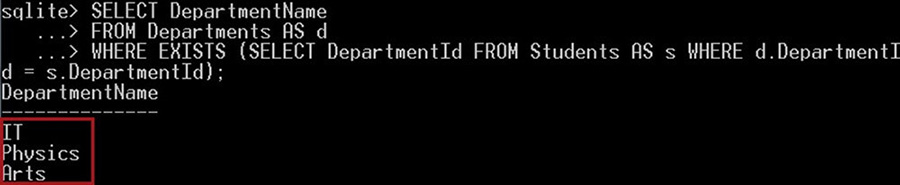
چنان که میبینید تنها سه دپارتمان IT ،Physics و Arts بازگشت یافتهاند. نام دپارتمان math بازگشت نیافته است، زیرا هیچ دانشجویی در این دپارتمان وجود ندارد، از این رو شناسه دپارتمان در جدول دانشجویان وجود ندارد. به همین جهت است که عملگر EXISTS دپارتمان math را نادیده گرفته است.
NOT در SQLite
این عملگر نتیجه عملگر قبل بعد از خود را معکوس میسازد. به مثالهای زیر توجه کنید:
- NOT BETWEEN – این عملگر در صورتی مقدار true بازگشت میدهد که BETWEEN مقدار false بازگشت دهد و برعکس.
- NOT LIKE – این عملگر در صورتی مقدار true بازگشت میدهد که LIKE مقدار false بازگشت دهد و برعکس.
- NOT GLOB – این عملگر در صورتی مقدار true بازگشت میدهد که GLOB مقدار false بازگشت دهد و برعکس.
- NOT EXISTS – این عملگر در صورتی مقدار true بازگشت میدهد که EXISTS مقدار false بازگشت دهد و برعکس.
مثال
در مثال زیر، از عملگر NOT به همراه عملگر EXISTS برای دریافت نام دپارتمانهایی که در جدول دانشجویان وجود ندارند، استفاده میکنیم. این عملگر معکوس عملگر EXISTS است. بنابراین جستجو از طریق DepartmentId که در جدول department نیستند صورت میگیرد:
SELECT DepartmentName
FROM Departments AS d
WHERE NOT EXISTS (SELECT DepartmentId
FROM Students AS s
WHERE d.DepartmentId = s.DepartmentId);خروجی به صورت زیر است:
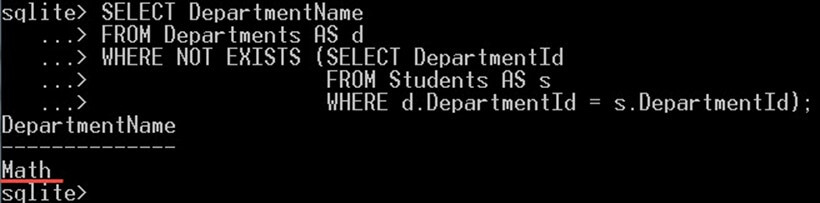
چنان که میبینید تنها دپارتمان math بازگشت مییابد. از آنجا که دپارتمان math تنها دپارتمان است که در جدول دانشجویان حضور ندارد بازگشت یافته است.
محدودسازی و مرتبسازی نتایج در SQLite
در این بخش برخی عملگرها که برای محدودسازی نتایج کوئریها و یا مرتبسازی نتایج در SQLite مورد استفاده قرار میگیرند را بررسی میکنیم.
Order در SQLite
عملگر Order برای مرتبسازی نتایج بر اساس یک یا چند عبارت مورد استفاده قرار میگیرد. برای مرتبسازی مجموعه نتایج باید از بند ORDER BY به صورت زیر استفاده کنیم:
- ابتدا باید بند ORDER BY را تعیین کنید.
- بند ORDER BY باید در انتهای کوئری تعیین شود، تنها بند ORDER BY میتواند پس از آن مشخص شود.
- عبارتی که برای مرتبسازی دادهها مورد استفاده قرار میگیرد، میتواند نام یک ستون یا یک عبارت مجزا باشد.
- پس از این عبارت باید یک جهت مرتبسازی اختیاری تعیین کنید. به این منظور میتوانید از DESC برای مرتبسازی نزولی یا از ASC برای مرتبسازی صعودی دادهها استفاده کنید. اگر هیچ کدام از آنها را تعیین نکنید، دادهها به صورت صعودی مرتبسازی میشوند.
- امکان تعیین عبارتهای بیشتر با استفاده از کاما (,) در بین عبارتها وجود دارد.
مثال
در مثال زیر همه دانشجویان را که بر اساس نامهایشان به صورت نزولی مرتبسازی شدهاند و سپس بر اساس نام دپارتمان به صورت صعودی مرتبسازی شدهاند انتخاب میکنیم:
SELECT s.StudentName, d.DepartmentName
FROM Students AS s
INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId
ORDER BY d.DepartmentName ASC, s.StudentName DESC;نتیجه به صورت زیر است:
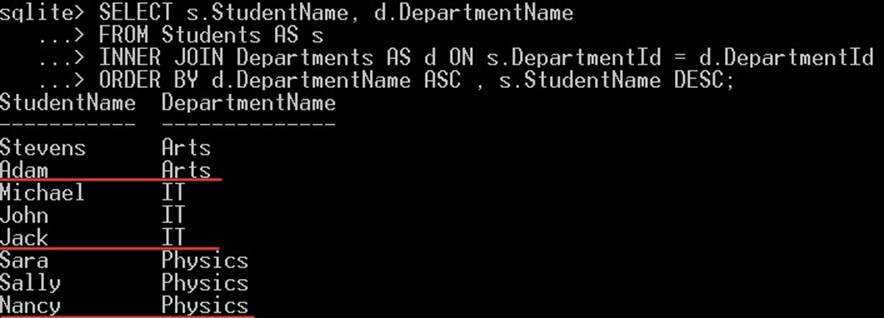
SQLite ابتدا همه دانشجویان را بر اساس نام دپارتمانشان با ترتیب صعودی مرتبسازی میکند.
سپس برای هر نام دپارتمان، همه دانشجویان که در آن دپارتمان هستند با ترتیب نزولی بر اساس نامهایشان نمایش مییابند.
Limit در SQLite
امکان محدودسازی ردیفهای بازگشتی از کوئری SQL با استفاده از بند LIMIT وجود دارد. برای نمونه LIMIT 10 موجب میشود که تنها 10 ردیف در نتایج بازگشت یابد و بقیه ردیفها نادیده گرفته شوند.
در بند LIMIT میتوانید یک تعداد خاصی از ردیفها را که از یک موقعیت خاص آغاز میشوند با استفاده از بند OFFSET انتخاب کنید. برای نمونه LIMIT 4 OFFSET 4 چهار ردیف نخست را نادیده میگیرد و 4 ردیف که از ردیف پنجم آغاز میشود را بازگشت خواهد داد، به این ترتیب ردیفهای 5، 6، 7 و 8 به دست میآیند.
توجه کنید که بند OFFSET اختیاری است و میتوانید کوئری فوق را به صورت LImIT 4,4 نیز بنویسید و نتایج دقیقاً یکسانی بازگشت خواهند یافت.
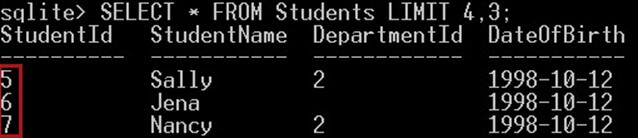
مثال
در مثال زیر تنها 3 دانشجو بازگشت مییابند و از شناسه 5 آغاز میشوند:
SELECT * FROM Students LIMIT 4,3;کوئری فوق نام سه دانشجو را که از ردیف پنجم آغاز میشوند ارائه میکند. بنابراین ردیفهای StudentId 5، شش و 7 ارائه میشود:
حذف موارد تکراری
اگر کوئری SQL مقادیر تکراری بازگشت دهد، میتوانید از کلیدواژه DISTINCT برای حذف موارد تکراری و بازگشت صرفاً موارد متمایز استفاده کنید. پس از کلیدواژه DISTINCT میتوان نام بیش از یک ستون را آورد.
مثال
کوئری زیر مقادیر تکراری برای نام دپارتمان بازگشت میدهد. در نتیجه این کوئری نامهای IT ،Physics و Arts تکرار میشوند:
SELECT d.DepartmentName
FROM Students AS s
INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;به این ترتیب مقادیر تکراری برای نام دپارتمان بازگشت مییابد:
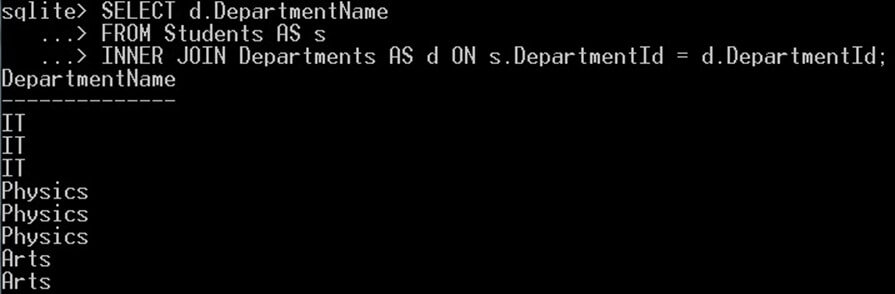
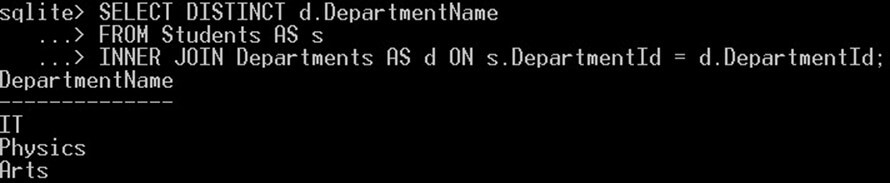
توجه کنید که نامهای دپارتمانها چگونه تکرار شده است. اکنون باید از کلیدواژه DISTINCT روی همان کوئری استفاده کنیم تا موارد تکراری حذف شده و تنها مقادیر یکتا برجا بمانند. به مثال زیر توجه کنید:
SELECT DISTINCT d.DepartmentName
FROM Students AS s
INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;کوئری فوق سه مقدار یکتا برای ستون نام دپارتمان بازگشت میدهد:
Aggregate در SQLite
Aggregate در SQLite به تابعهای داخلی SQLite گفته میشود که مقادیر چندگانه از چندین ردیف را در یک ردیف ترکیب میکنند. در ادامه برخی موارد از تابعهای Aggregate را در SQL بررسی میکنیم.
()AVG
میانگین همه مقادیر x را بازگشت میدهد.
مثال
در مثال زیر میانگین نمرات دانشجویان را از همه آزمونها به دست میآوریم:
SELECT AVG(Mark) FROM Marks;کوئری فوق نتیجه زیر را به دست میدهد:
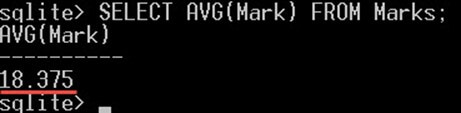
این نتیجه از جمع زدن همه نمرات و سپس تقسیم کردن آن بر تعداد نمرات به دست میآید.
()COUNT به صورت COUNT(X) یا (*)COUNT
این تابع مجموع کل تعداد دفعاتی که مقدار x در یک ستون ظاهر شده است را بازگشت میدهد. برخی گزینهها نیز وجود دارند که میتوان به همراه COUNT استفاده کرد:
- COUNT(x) – تنها مقادیر x را میشمارد که x نام ستون است. این تابع مقادیر NULL را نادیده میگیرد.
- (*)COUNT – همه ردیفها را از همه ستونها میشمارد.
- COUNT (DISTINCT x) – میتوان با استفاده از کلیدواژه DISTINCT پیش از x تعداد مقادیر متمایز x را به دست آورد.
مثال
در مثال زیر مجموع کل دپارتمانها را با سه کوئری مختلف به دست آوردهایم و نتایج را با هم مقایسه میکنیم:
SELECT COUNT(DepartmentId), COUNT(DISTINCT DepartmentId), COUNT(*) FROM Students;نتیجه به صورت زیر است:

بدین ترتیب:
- COUNT(DepartmentId) تعداد همه شناسههای دپارتمان را به دست میدهد و مقادیر تهی را نادیده میگیرد.
- COUNT(DISTINCT DepartmentId) مقادیر متمایز DepartmentId را ارائه میکند که تنها 3 مورد هستند. دقت کنید که 8 مقدار برای نام دپارتمان وجود دارند، اما تنها سه مقدار به صورت متمایز از هم شامل Math, IT و Physics هستند.
- (*)COUNT تعداد ردیفهای جدول دانشجویان را که 10 ردیف برای 10 دانشجو است ارائه میکند.
GROUP_CONCAT
تابعهای مختلف GROUP_CONCAT چندین مقدار را در یک مقدار منفرد که با کاما از هم جدا شده است تجمیع میکنند. گزینههای این تابع به صورت زیر هستند:
- GROUP_CONCAT(X) – این تابع همه مقادیر x را در یک رشته واحد تجمیع میکند که با کاما از هم جدا شدهاند. مقادیر تهی نادیده گرفته میشوند.
- GROUP_CONCAT(X, Y) – این تابع مقادیر x را در یک رشته واحد تجمیع میکند به طوری که به جای کاما از y به عنوان جداکننده بین هر مقدار استفاده میشود. مقادیر تهی نادیده گرفته خواهند شد.
- GROUP_CONCAT(DISTINCT X) – این تابع همه مقادیر متمایز x را در یک رشته تجمیع میکند که با کاما از هم جدا شدهاند. مقادیر تهی نادیده گرفته میشوند.
مثال GROUP_CONCAT(DepartmentName)
کوئری زیر همه مقادیر نام دپارتمان را از جدول دانشجویان و دپارتمانها انتخاب کرده و در یک رشته منفرد که با کاما جدا میشود تجمیع میکند. بنابراین به جای بازگشت دادن یک لیست از مقادیر که در هر ردیف یک مقدار وجود دارد، تنها یک مقدار روی هر ردیف بازگشت مییابد و همه مقادیر با کاما از هم جدا میشوند:
SELECT GROUP_CONCAT(d.DepartmentName)
FROM Students AS s
INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;نتیجه به صورت زیر است:

به این ترتیب فهرستی از 8 نام دپارتمان که در یک رشته جداشده با کاما تجمیع شدهاند در اختیار ما قرار میگیرد.
مثال GROUP_CONCAT(DISTINCT DepartmentName)
کوئری زیر مقادیر متمایز نام دپارتمان را از جدول دانشجویان و دپارتمانها در یک رشته منفرد جدا شده با کاما تجمیع میکند:
SELECT GROUP_CONCAT(DISTINCT d.DepartmentName)
FROM Students AS s
INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;کوئری فوق نتیجه زیر را تولید میکند:

به متفاوت بودن نتیجه با نتیجه قبلی توجه کنید. تنها سه مقدار بازگشت یافتهاند که نامهای دپارتمانهای متمایز هستند و مقادیر تکراری حذف شدهاند.
مثال GROUP_CONCAT(DepartmentName,’&’)
کوئری زیر همه مقادیر را از ستون نام دپارتمان در جدولهای دانشجویان و دپارتمانها در یک رشته واحد تجمیع میکند، اما از کاراکتر & به جای کاما برای جدا کردن آنها استفاده میکند:
SELECT GROUP_CONCAT(d.DepartmentName, '&')
FROM Students AS s
INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;نتیجه کوئری فوق به صورت زیر است:

توجه کنید که چطور & به جای جداکننده پیشفرض کاما (,) برای جداسازی مقادیر در رشته استفاده شده است.
()MAX و ()MIN در SQLite
()MAX بالاترین مقدار را از بین مقادیر X بازگشت میدهد. در صورتی که همه مقادیر X تهی باشند، MAX مقدار NUL بازگشت میدهد. در حالی که MIN(X) کوچکترین مقدار را از بین مقادیر X باز میگرداند. در صورتی که همه مقادیر X تهی باشند، MIN نیز مقدار NULL بازگشت میدهد.
مثال
در کوئری زیر، از تابعهای MIN و MAX برای دریافت بالاترین و پایینترین نمره از جدول Marks استفاده کردهایم:
SELECT MAX(Mark), MIN(Mark) FROM Marks;کوئری فوق نتیجه زیر را تولید میکند:

SUM(x) و Total(x) در SQLite
هر دوی این تابعها مجموع همه مقادیر X را بازگشت میدهند. اما بر حسب شرایط زیر متفاوت هستند:
- در صورتی که همه مقادیر تهی باشند، SUM مقدار NULL بازگشت میدهد، اما مجموع برابر با صفر است.
- TOTAL همواره مقادیر اعشاری بازگشت میدهد. SUM در صورتی که مقادیر X عدد صحیح باشند یک عدد صحیح بازگشت میدهد. با این حال اگر مقادیر عدد صحیح نباشند، یک مقدار اعشاری بازگشت میدهد.
مثال
در کوئری زیر، از SUM و TOTAL برای دریافت مجموع همه نمرات در جدول Marks استفاده میکنیم:
SELECT SUM(Mark), TOTAL(Mark) FROM Marks;کوئری فوق نتیجه زیر را ایجاد میکند:

چنان که میبینید TOTAL همواره یک مقدار اعشاری بازگشت میدهد. اما SUM یک مقدار صحیح بازگشت میدهد، زیرا مقادیر در ستون Mark ممکن است عدد صحیح باشند.
مثالی برای تفاوت بین SUM و TOTAL
در کوئری زیر تفاوت بین SUM و TOTAL در زمان دریافت مجموع مقادیر تهی را میبینید:
SELECT SUM(Mark), TOTAL(Mark) FROM Marks WHERE TestId = 4;کوئری فوق نتیجه زیر را تولید میکند:

توجه کنید که هیچ نمرهای برای TestId = 4 وجود ندارد، زیرا این تست مقدار تهی دارد. بدین ترتیب SUM یک مقدار تهی به صورت خالی بازگشت میدهد در حالی که TOTAL مقدار 0 بازگشت میدهد.
Group BY
بند Group BY برای تعیین یک یا چند ستون برای گروهبندی ردیفها در یک گروه مورد استفاده قرار میگیرد. این ردیفها با مقادیر یکسان به همراه هم در یک گروه جمع میشوند.
در مورد هر ستون دیگر که در ستونهای Group BY قرار نگیرد، میتوانید از تابع aggregate استفاده کنید.
مثال
کوئری زیر مجموع کل دانشجویانی که در هر دپارتمان حضور دارند را ارائه میکند.
SELECT d.DepartmentName, COUNT(s.StudentId) AS StudentsCount
FROM Students AS s
INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId
GROUP BY d. DepartmentName;نتیجه کوئری فوق به صورت زیر است:
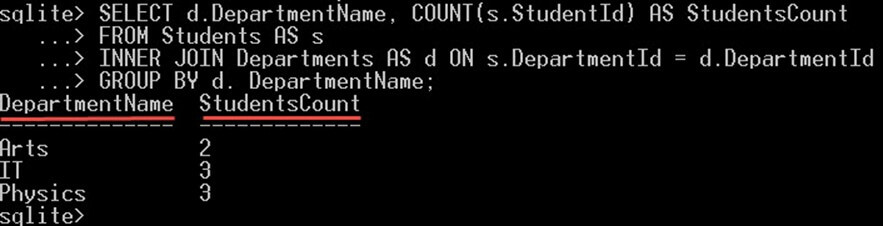
بند GROUPBY DepartmentName موجب گروهبندی همه دانشجویان در گروههایی با نام دپارتمانها میشود. برای هر گروه از دپارتمانها تعداد دانشجویان شمارش میشود.
بند HAVING
اگر بخواهید گروههای بازگشتی از سوی بند GROUP BY را گروهبندی کنید، در این صورت میتوانید یک بند HAVING با یک عبارت پس از GROUP BY تعیین کنید. این عبارت برای فیلتر کردن گروهها مورد استفاده قرار میگیرد.
مثال
در کوئری زیر آن دپارتمانهایی که تنها دو دانشجو در خود دارند انتخاب میشوند:
SELECT d.DepartmentName, COUNT(s.StudentId) AS StudentsCount
FROM Students AS s
INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId
GROUP BY d. DepartmentName
HAVING COUNT(s.StudentId) = 2;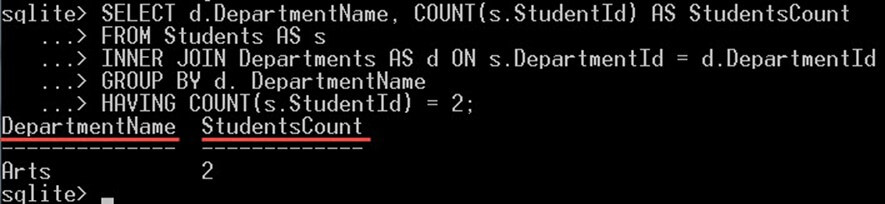
بند HAVING COUNT(S.StudentId) = 2 موجب فیلتر شدن گروههای بازگشتی میشود و تنها آن گروههایی را بازگشت میدهد که شامل دقیقاً دو دانشجو در خود باشند. در این مورد دپارتمان هنر (Arts) 2 دانشجو دارد و از این رو در خروجی نمایش یافته است.
Query و Subquery در دیتابیس SQLite
درون هر کوئری میتوانید از یک کوئری دیگر در یک بند SELECT ،INSERT ،DELETE ،UPDATE یا درون یک کوئری فرعی دیگر استفاده کنید. این کوئری تودرتو به نام «کوئری فرعی» (Subquery) خوانده میشود. در ادامه برخی مثالها از استفاده از کوئریهای فرعی در بند SELECT را بررسی خواهیم کرد. با این حال در بخش بعدی با عنوان «تغییر دادن دادهها» با شیوه استفاده از کوئریهای فرعی با گزارههای INSERT ،DELETE و UPDATE نیز آشنا خواهیم شد.
مثالی برای استفاده از کوئری فرعی در بند FROM
در کوئری زیر یک کوئری فرعی درون بند FROM قرار دادهایم:
SELECT
s.StudentName, t.Mark
FROM Students AS s
INNER JOIN
(
SELECT StudentId, Mark
FROM Tests AS t
INNER JOIN Marks AS m ON t.TestId = m.TestId
) ON s.StudentId = t.StudentId;کوئری زیر در این جا کوئری فرعی نام دارد، زیرا درون یک بند FROM قرار گرفته است. توجه کنید که ما یک اسم مستعار t به آن دادهایم تا بتوانیم در ستونهای بازگشتیِ کوئری به آن اشاره کنیم:
SELECT StudentId, Mark
FROM Tests AS t
INNER JOIN Marks AS m ON t.TestId = m.TestIdنتیجه کوئری فوق به صورت زیر است:
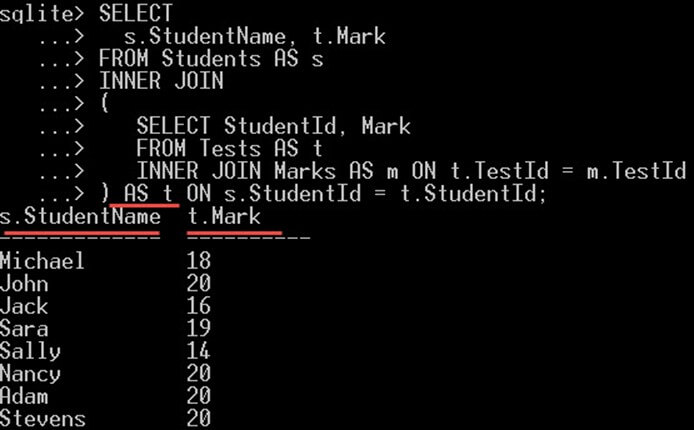
بنابراین در این مورد میتوانیم نتایج را به صورت زیر جمعبندی کنیم.
s.StudentName از کوئری اصلی که نام دانشجو را میدهد انتخاب میشود و در ادامه t.Mark از کوئری فرعی انتخاب میشود که نمرات به دست آمده برای هر یک از این دانشجوها را ارائه میکند.
مثالی برای استفاده از کوئری فرعی با بند WHERE
در کوئری زیر یک کوئری فرعی در بند WHERE قرار دادهایم:
SELECT DepartmentName
FROM Departments AS d
WHERE NOT EXISTS (SELECT DepartmentId
FROM Students AS s
WHERE d.DepartmentId = s.DepartmentId);کوئری زیر یک کوئری فرعی نام دارد، زیرا درون بند WHERE قرار گرفته است. این کوئری فرعی مقادیر DepartmentId را که از سوی عملگر NOT EXISTS استفاده میشود، بازگشت میدهد:
SELECT DepartmentId
FROM Students AS s
WHERE d.DepartmentId = s.DepartmentIdنتیجه کوئری فوق به صورت زیر است:
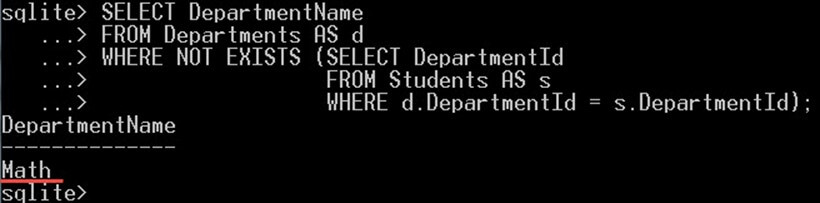
در کوئری فوق، دپارتمانی را که هیچ دانشجویی در آن ثبت نام نکرده است، انتخاب کردهایم. در این مثال این دپارتمان Math است.
عملگرهای مجموعهای UNION و Intersect در SQLite
SQLite از برخی عملگرهای مجموعه پشتیبانی میکند که در ادامه آنها را بررسی میکنیم.
UNION و UNION ALL
این عملگر یک یا چند مجموعه حاصل (گروهی از ردیفها) را که از چند گزاره SELECT بازگشت یافتهاند در یک مجموعه منتج ترکیب میکند. UNION مقادیر متمایز را بازگشت میدهد. با این حال UNION ALL این حالت را ندارد و موارد تکراری را نیز شامل میشود.
توجه کنید که نام ستون همان نام ستون تعیین شده در گزاره SELECT خواهد بود.
مثال UNION
در مثال زیر، فهرستی از DepartmentId را از جدول دانشجویان میگیریم و فهرست DepartmentId دیگر را نیز از جدول دپارتمانها در همان ستون میگیریم:
SELECT DepartmentId AS DepartmentIdUnioned FROM Students
UNION
SELECT DepartmentId FROM Departments;بدین ترتیب نتیجه زیر حاصل میشود:
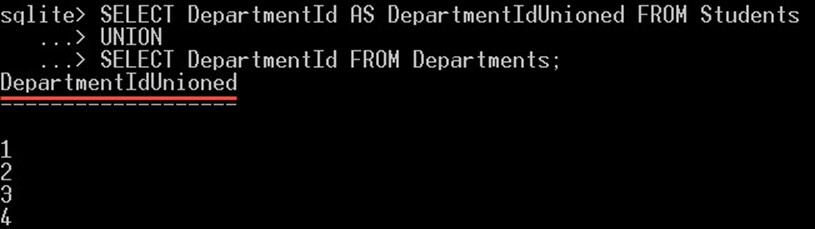
این کوئری تنها 5 ردیف بازگشت میدهد که مقادیر شناسه متمایز هستند. به مقدار نخستی که NULL است توجه کنید.
مثالی برای UNION ALL در SQLite
در مثال زیر فهرستی از DepartmentId را از جدول دانشجویان میگیریم و فهرست DepartmentId را از جدول دپارتمانها در همان ستون دریافت میکنیم:
SELECT DepartmentId AS DepartmentIdUnioned FROM Students
UNION ALL
SELECT DepartmentId FROM Departments;نتیجه کوئری فوق به صورت زیر است:
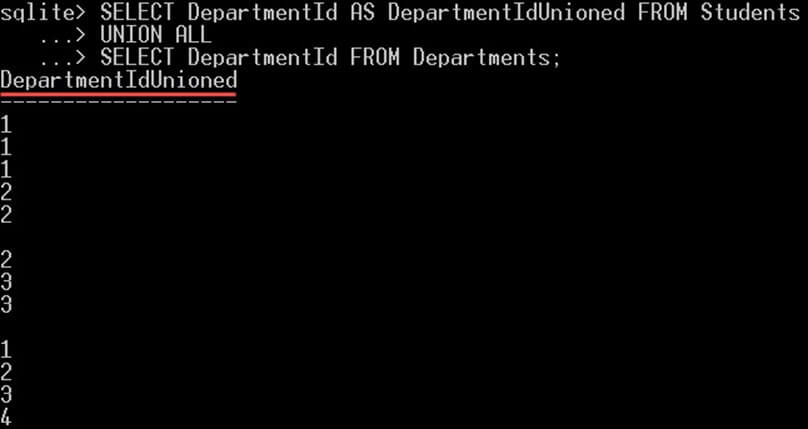
این کوئری 14 ردیف بازگشت میدهد که 10 ردیف از جدول دانشجویان و 4 ردیف از جدول دپارتمانها است. توجه داشته باشید که موارد تکراری نیز در میان مقادیر بازگشت یافتهاند. ضمناً توجه کنید که نام ستون آن نامی است که در گزاره اول SELECT قید شده است.
در ادامه بررسی میکنیم که UNION ALL چطور همه نتایج را به دست میدهد.
INTERSECT در SQLite
INTERSECT همه مقادیر موجود در دو مجموعه ترکیب شده را بازگشت میدهد. مقادیری که فقط در یکی از دو مجموعه ترکیب شده وجود داشته باشند، نادیده گرفته میشوند.
مثال
در کوئری زیر، مقادیر DepartmentId را که در هر دو جدول دانشجویان و دپارتمانها باشند در ستون DepartmentId انتخاب میکنیم:
SELECT DepartmentId FROM Students
Intersect
SELECT DepartmentId FROM Departments;نتیجه به صورت زیر است:
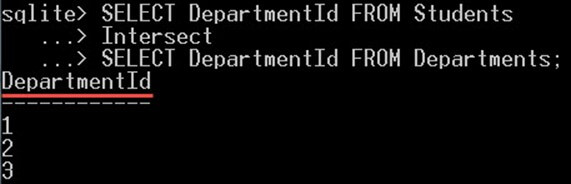
این کوئری سه مقدار 1، 2 و 3 را بازگشت میدهد. اینها مقادیری هستند که در هر دوی جدولها حضور دارند.
با این حال، مقادیر تهی و 4 ارائه نشدهاند، زیرا مقدار تهی تنها در جدول دانشجویان حضور دارد و در جدول دپارتمانها وجود ندارد. مقدار 4 نیز در جدول دپارتمانها حضور دارد و در جدول دانشجویان موجود نیست.
به همین جهت است که هر دو مقدار تهی و 4 نادیده گرفته شدهاند و در مقادیر بازگشتی حضور ندارند.
EXCEPT
فرض کنید دو لیست از ردیفها دارید که list1 و list2 نام دارند و میخواهید تنها آن اعضای لیست 1 را انتخاب کنید که در لیست 2 نباشند.
مثال
در کوئری زیر مقادیر DepartmentId را که در جدول دپارتمانها وجود دارند و در جدول دانشجویان وجود ندارند، انتخاب میکنیم:
SELECT DepartmentId FROM Departments
EXCEPT
SELECT DepartmentId FROM Students;نتیجه کوئری فوق به صورت زیر است:
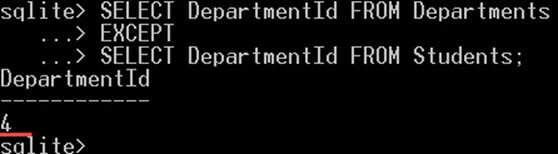
این کوئری تنها مقدار 4 را بازگشت میدهد. این تنها مقداری است که در جدول دپارتمانها وجود دارد و در جدول دانشجویان حضور ندارد.
مدیریت NULL
مقدار NULL یک مقدار خاص در SQLite است. از این مقدار برای بازنمایی مقادیر نامشخص یا مفقود استفاده میشود. توجه کنید که مقدار NULL به طور کلی متفاوت از 0 یا مقدار خالی “” است. زیرا 0 و مقدار خالی یک مقدار شناخته شده دارد، اما مقدار تهی نامشخص است.
مقادیر NULL نیازمند مدیریت خاصی در SQLite هستند. در ادامه این روش مدیریت مقادیر NULL را بررسی میکنیم.
جستجو به دنبال مقادیر NULL
امکان استفاده از عملگر برابری (=) به طور معمول برای گشتن به دنبال مقادیر NULL وجود ندارد. برای نمونه کوئری زیر به دنبال دانشجویانی میگردد که مقدار دپارتمان تهی دارند:
SELECT * FROM Students WHERE DepartmentId = NULL;این کوئری هیچ نتیجهای به دست نمیدهد:

از آنجا که مقدار NULL برابر با هیچ مقدار دیگری که مقداری داشته باشد نیست، نمیتواند هیچ نتیجهای بازگشت بدهد.
برای این که این کوئری کار کند باید از عملگر IS NULL برای گشتن به دنبال مقادیر تهی به صورت زیر استفاده کنید:
SELECT * FROM Students WHERE DepartmentId IS NULL;نتیجه اجرای کوئری فوق به صورت زیر است:

این کوئری آن دانشجویانی را بازگشت میدهد که مقدار دپارتمانشان تهی است. اگر بخواهید مقادیری را به دست آورید که تهی نیستند، باید از عملگر IS NOT NULL به صورت زیر استفاده کنید:
SELECT * FROM Students WHERE DepartmentId IS NOT NULL;این کوئری نتیجه زیر را تولید میکند:
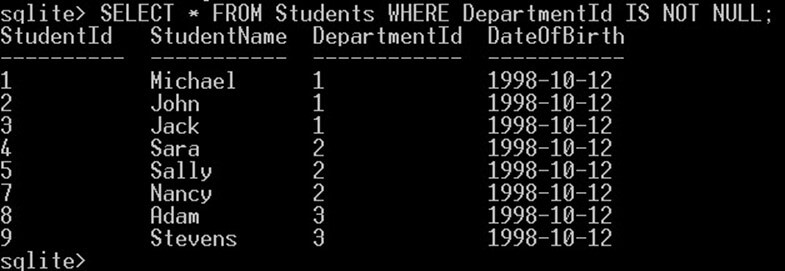
این کوئری دانشجویانی را بازگشت میدهد که مقدار دپارتمان تهی ندارند.
نتایج شرطی
اگر لیستی از مقادیر داشته باشید و بخواهید هر یک از آنها را بر اساس یک شرط انتخاب کنید، باید یک شرط تعیین کنید که فقط برای آن مقدار معین مقدار true بازگشت دهد. عبارت CASE این لیست از شرایط را برای همه مقادیر بررسی میکند و اگر شرط true باشد آن مقدار را بازگشت خواهد داد. برای نمونه اگر یک ستون به نام Grade داشته باشید و بخواهید یک مقدار متنی بر اساس گرید به صورت زیر انتخاب کنید، میتوانید از عبارت CASE به این منظور بهره بگیرید:
- در صورتی که گرید بالاتر از 85 باشد، نتیجه عالی (Excellent) است.
- در صورتی که گرید بین 10 و 85 باشد، نتیجه بسیار خوب (Very Good) است.
- در صورتی که گرید بین 60 و 70 باشد، نتیجه خوب (Good) است.
از این موارد میتوان برای تعریف منطق در بند SELECT استفاده کرد، به طوری که بتوان نتایج خاصی را بسته به شرایط انتخاب کرد. عملگر CASE را میتوان با ساختارهای متفاوتی مانند زیر تعریف کرد.
میتوان از شرایط مختلف استفاده کرد:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN condition3 THEN result3
…
ELSE resultn
ENDهمچنین میتوان تنها از یک عبارت استفاده کرد و مقادیر مختلف ممکن را اضافه کرد:
CASE expression
WHEN value1 THEN result1
WHEN value2 THEN result2
WHEN value3 THEN result3
…
ELSE restuln
ENDتوجه کنید که بند ELSE اختیاری است.
مثال
در مثال زیر از عبارت CASE با مقدار NULL در ستون شناسه دپارتمان در جدول Students برای نمایش متن No Department مانند زیر استفاده کردهایم:
SELECT
StudentName,
CASE
WHEN DepartmentId IS NULL THEN 'No Department'
ELSE DepartmentId
END AS DepartmentId
FROM Students;
- عملگر CASE بررسی میکند آیا مقدار DepartmentId تهی است یا نه.
- اگر مقدار تهی باشد، در این صورت مقدار لفظی No Department به جای مقدار DepartmentId انتخاب میشود.
- اگر مقدار تهی نباشد، در این صورت مقدار ستون DepartmentId انتخاب میشود.
بدین ترتیب نتیجهای مانند زیر به دست میآید:
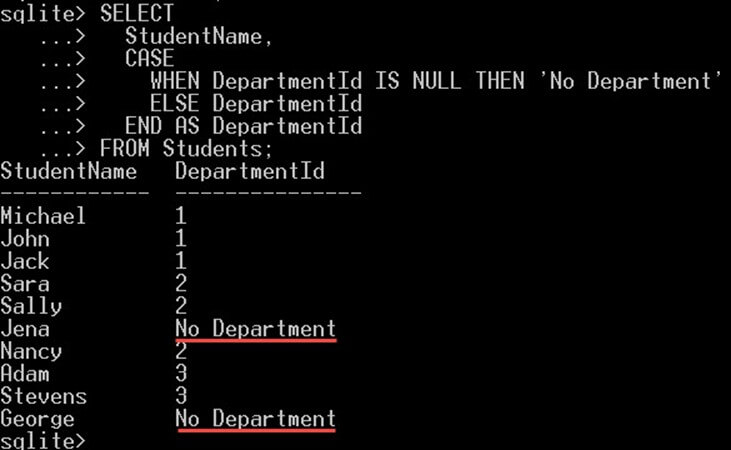
عبارتهای رایج جدول SQLite
«عبارتهای رایج جدول» (CTE) آن دسته از کوئریهای فرعی هستند که درون گزاره SQL با یک نام مفروض تعریف میشوند. این عبارتها نسبت به کوئریهای فرعی مزیتهایی دارند، زیرا خارج از گزاره SQL تعریف میشوند و موجب سهولت خوانده شدن، نگهداری و درک کوئریها میشوند.
یک عبارت رایج جدول را میتوان با قرار دادن بند WITH در ابتدای گزاره SELECT به صورت زیر تعریف کرد:
WITH CTEname
AS
(
SELECT statement
)
SELECT, UPDATE, INSERT, or update statement here FROM CTECTEname هر نامی است که میتوان به یک CTE داد. شما میتوانید از آن برای ارجاعهای آتی استفاده کنید. توجه کنید که امکان تعریف گزاره SELECT, UPDATE, INSERT یا DELETE روی CTE وجود دارد. در ادامه به بررسی مثالی از چگونگی استفاده از CTE در بند SELECT میپردازیم.
مثال
در مثال زیر یک CTE از گزاره SELECT تعریف میکنیم و سپس از آن در ادامه در کوئریهای دیگر استفاده میکنیم:
WITH AllDepartments
AS
(
SELECT DepartmentId, DepartmentName
FROM Departments
)
SELECT
s.StudentId,
s.StudentName,
a.DepartmentName
FROM Students AS s
INNER JOIN AllDepartments AS a ON s.DepartmentId = a.DepartmentId;در این کوئری یک CTE تعریف کرده و نام آن را AllDepartments تعریف میکنیم. این CTE از یک کوئری SELECT تعریف شده است:
SELECT DepartmentId, DepartmentName
FROM Departmentsسپس CTE را که در کوئری SELECT بعدی استفاده میکنیم تعریف کردهایم.
توجه کنید که عبارتهای رایج جدول روی خروجی کوئری تأثیر دارند. این یک روش برای تعریف یک نمای منطقی یا کوئری فرعی برای استفاده مجدد از آنها در همان کوئری است. عبارتهای رایج جدولی مانند یک متغیر هستند که اعلان میشوند و سپس به صورت یک کوئری فرعی مجدداً استفاده میشوند. تنها گزاره SELECT بر روی خروجی کوئری تأثیر میگذارد. نتیجه کوئری فوق به صورت زیر است:
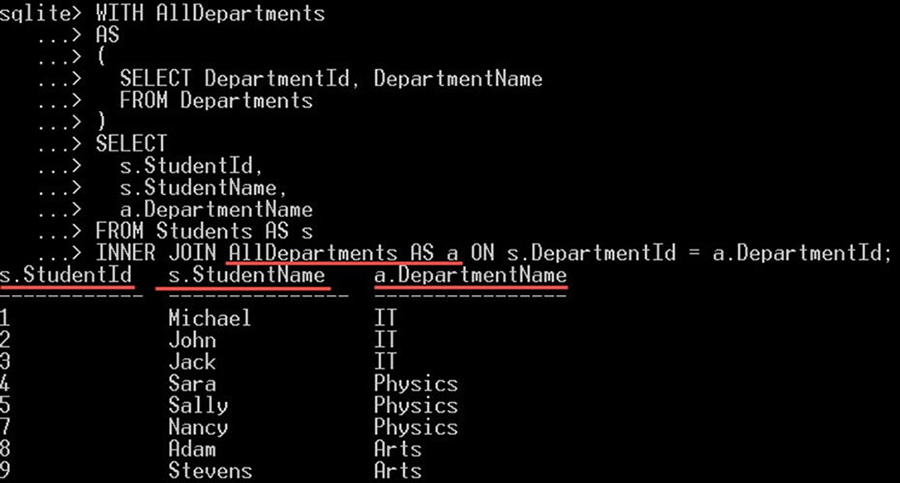
کوئریهای پیشرفته SQLite
کوئریهای پیشرفته به کوئریهایی گفته میشود که شامل JOIN-ها یا کوئریهای پیچیده فرعی و برخی تجمیعها هستند. در بخش بعدی به بررسی یک مثال از کوئری پیچیده را میپردازیم. در این کوئری موارد زیر را به دست میآوریم:
- نامهای دپارتمانها با همه دانشجویان هر دپارتمان
- نام دانشجویان که با کاما از هم جدا شدهاند.
- دپارتمانهایی که دستکم سه دانشجو دارند را نمایش میدهیم.
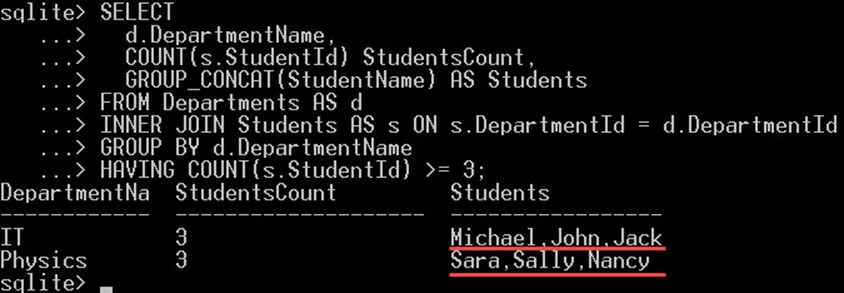
SELECT
d.DepartmentName,
COUNT(s.StudentId) StudentsCount,
GROUP_CONCAT(StudentName) AS Students
FROM Departments AS d
INNER JOIN Students AS s ON s.DepartmentId = d.DepartmentId
GROUP BY d.DepartmentName
HAVING COUNT(s.StudentId) >= 3;یک بند JOIN برای به دست آوردن DepartmentName از جدول Departments اضافه میکنیم. پس از این که بند GROUP BY را با دو تابع تجمیع اضافه کردیم، اتفاقات زیر میافتند:
- COUNT برای شمارش دانشجویان هر گروه دپارتمان استفاده میشود.
- GROUP_CONCAT برای الحاق دانشجویانی از هر گروه به یک رشته منفرد که با کاما از هم جدا شدهاند استفاده میشود.
- پس از GROUP BY از بند HAVING برای فیلتر کردن دپارتمانها و انتخاب صرف مواردی که دارای دستکم 3 دانشجو هستند بهره میگیریم.
نتیجه به صورت زیر است:
جمعبندی بخش کوئریها
در این بخش به بررسی روش نوشتن کوئریهای SqLite پرداختیم و با مبانی کوئری زدن به دیتابیس و شیوه فیلتر کردن دادههای بازگشتی آشنا شدیم. اینک شما با روش نوشتن کوئریهای SQLite آشنا شدهاید. در بخش بعدی به بررسی روشهای مختلف JOIN کردن جداول SQLite میپردازیم.
بررسی انواع JOIN در SQLite به همراه مثال
SQLite از انواع مختلفی از Join-های SQL شامل INNER JOIN, LEFT OUTER JOIN و CROSS JOIN پشتیبانی میکند. هر نوع از JOIN برای موقعیت متفاوتی مورد استفاده قرار میگیرد که در این بخش از آموزش دیتابیس SQLite آنها را بررسی میکنیم.
مقدمهای بر بند JOIN در SQLite
زمانی که با یک دیتابیس که چندین جدول دارد کار میکنید، در اغلب موارد باید دادهها را از چند جدول دریافت کنید. با استفاده از بند JOIN میتوان یک یا چند جدول یا کوئری فرعی را به هم اتصال داد. ضمناً میتوان ستونی را که باید جدولها را به آن پیوند داد و شرط مربوطه را تعریف کرد. هر بند JOIN باید دارای ساختار زیر باشد:

هر بند JOIN شامل موارد زیر است:
- یک جدول یا کوئری فرعی که جدول چپ است؛ جدول یا کوئری فرعی پیش از بند JOIN (در سمت چپ آن)
- عملگر JOIN – نوع JOIIN را مشخص میکند و میتواند یکی از انواع INNER JOIN, LEFT OUTER JOIN یا CROSS JOIN باشد.
- قید JOIN – پس از این که جدولها و کوئریهای فرعی که باید اتصال یابند را مشخص ساختید، باید یک قید اتصال نیز مشخص کنید که یک شرط است که ردیفها در صورت تطبیق با این شرط بسته به نوع JOIN انتخاب میشوند.
توجه کنید که در مثالهای زیر باید فایل sqlite3.exe را اجرا کنید و یک اتصال با دیتابیس نمونه به صورت زیر برقرار سازید:
ابتدا My Computer را باز کرده و به مسیر دایرکتوری C:sqlite رفته و فایل sqlite3.exe را باز کنید.

اینک میتوانید هر نوع کوئری را روی دیتابیس اجرا کنید.
INNER JOIN در SQLite
INNER JOIN تنها ردیفهایی را بازگشت میدهد که شرط JOIN را داشته باشند و همه ردیفهای دیگر را که با این شرط مطابقت ندارند حذف میکند.
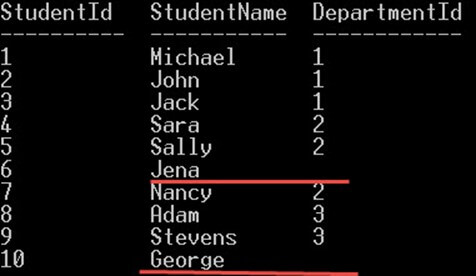
مثال
در مثال زیر دو جدول به نامهای Students و Departments را با DepartmentId به هم Join میکنیم تا نام دپارتمان را برای هر دانشجو به صورت زیر به دست آوریم:
SELECT
Students.StudentName,
Departments.DepartmentName
FROM Students
INNER JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;در کد فوق INNER JOIN به صورت زیر عمل میکند:
- در بند SELECT میتوانید تعیین کنید کدام ستونها از دو جدول ارجاع یافته انتخاب شوند.
- بند INNER JOIN پس از جدول اول که با بند FROM ارجاع مییابد نوشته میشود.
- سپس شرط JOIN با کلیدواژه ON مشخص شده است.
- میتوان برای جداول ارجاع یافته از اسامی مستعار (ALIAS) استفاده کرد.
- کلمه INNER اختیاری است و میتوان فقط JOIN را نوشت.
خروجی کد فوق به صورت زیر است:
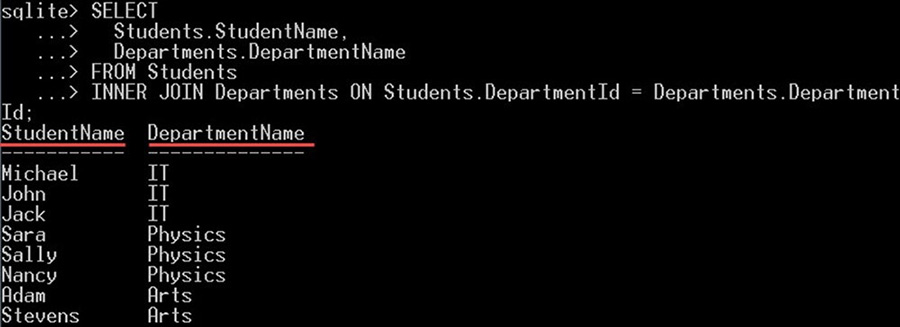
در خروجی فوق میبینیم که INNER JOIN رکوردهایی را از هر دو جدول دانشجویان و دپارتمانها که با شرط مورد نظر تطبیق یافتهاند ارائه کرده است. شرط ما به صورت زیر تعریف شده است:
Students.DepartmentId = Departments.DepartmentIdردیفهای تطبیق نیافته نادیده گرفته میشوند و در خروجی ارائه نشدهاند.
به همین دلیل است که 8 دانشجو از 10 دانشجو از این کوئری در دپارتمانهای IT ،Math و Physics بازگشت یافتهاند. در حالی که دانشجویانی به نام Jena و George در نتایج دیده نمیشوند زیرا شناسه دپارتمان آنها تهی است، یعنی ستون departmentId از جدول departments تطبیق نیافته است. در تصویر زیر این موضوع به خوبی دیده میشود:
JOIN … USING در SQLite
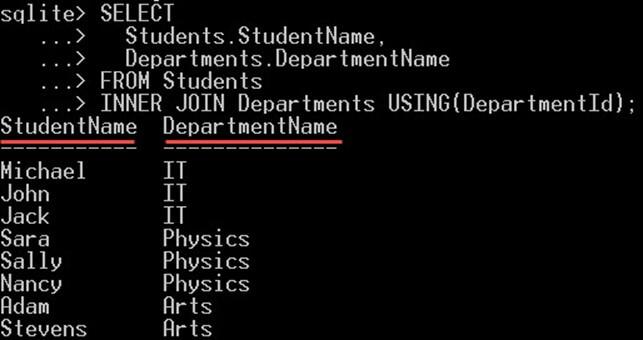
INNER JOIN را میتوان با استفاده از بند USING نیز نوشت تا از تکرار جلوگیری کرد. به این ترتیب به جای نوشتن چیزی مانند زیر:
ON Students.DepartmentId = Departments.DepartmentIdکافی است آن را به صورت زیر بنویسید:
USING(DepartmentID)امکان استفاده از USING(DepartmentID) روی هر ستون با نام یکسان برای مقایسه شرط JOIN وجود دارد. در چنین مواردی نیازی به تکرار آنها با استفاده از شرط وجود ندارد و کافی است نامهای ستون را مشخص کنید تا SQLite آنها را شناسایی کند.
تفاوت بین INNER JOIN و JOIN.. USING
در زمان استفاده از JOIN … USING شرط الحاق را نمینویسیم و صرفاً ستون مشترک بین دو جدول Join-شده را مینویسیم. بنابراین به جای این که کدی به صورت زیر مینویسیم:
INNER JOIN table2 ON table1.cola = table2.colaکوئری را به صورت زیر مینویسیم:
table1 JOIN table2 USING(cola)مثال
در مثال زیر دو جدول Students و Departments را با ستون DepartmentId به هم Join میکنیم تا نام دپارتمان هر دانشجو را مشخص سازیم:
SELECT
Students.StudentName,
Departments.DepartmentName
FROM Students
INNER JOIN Departments USING(DepartmentId);
- در کوئری فوق برخلاف مثال قبلی، کدی مانند ON Students.DepartmentId = Departments.DepartmentId ننوشتیم و صرفاً از USING(DepartmentId) استفاده کردیم.
- SQLite شرط الحاق را به طور خودکار تشخیص داده و DepartmentId را در هر دو جدول دانشجویان و دپارتمانها با هم مقایسه میکند.
- امکان استفاده از این ساختار در هرجایی که دو ستون که مقایسه میشوند دارای نام یکسانی باشند وجود دارد.
خروجی کد فوق به صورت زیر است. چنان که میبینید نتیجه دقیقاً مشابه مثال قبلی است:
NATURAL JOIN در SQLite
NATURAL JOIN نیز مشابه JOIN…USING است، تنها تفاوت این است که به صورت خودکار برابری بین مقادیر هر ستون که در هر دو جدول وجود دارد را مقایسه میکند.
در INNER JOIN باید یک شرط Join تعیین کنیم که برای الحاق دو جدول استفاده میشود. ما صرفاً نام دو جدول را بدون هیچ شرطی مینویسیم. سپس NATURAL JOIN به صورت خودکار برابری بین مقادیر هر ستون دو جدول را بررسی میکند. بدین ترتیب NATURAL JOIN شرط Join را به صورت خودکار استنباط میکند.
در NATURAL JOIN همه ستونهای هر و جدول با نام یکسان با همدیگر تطبیق مییابند. برای نمونه اگر دو جدول با دو نام ستون مشترک داشته باشیم (یعنی دو ستون با عنوان مشترک در دو جدول وجود داشته باشد)، در این صورت NATURAL JOIN دو جدول را با مقایسه کردن مقادیر هر دو ستون و نه فقط یک ستون به هم الحاق میکند.
مثال
SELECT
Students.StudentName,
Departments.DepartmentName
FROM Students
Natural JOIN Departments;در کوئری فوق برخلاف INNER JOIN نیازی به نوشتن شرط Join با نام ستون وجود ندارد. حتی برخلاف JOIN USING نیازی به نوشتن نام ستون برای یک بار نیز وجود ندارد.
NATURAL JOIN هر دو ستون را از دو جدول بررسی میکند. NATURAL JOIN تشخیص میدهد که باید DepartmentId را از دو جدول دانشجویان و دپارتمانها با هم مقایسه کند.
خروجی کد فوق به صورت زیر است:
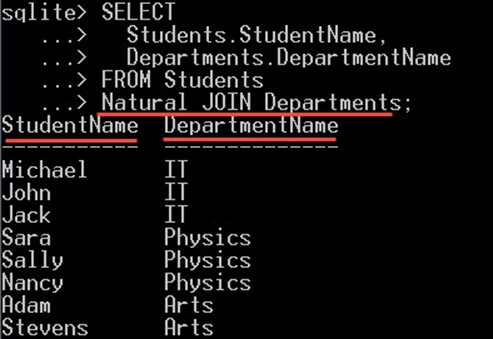
NATURAL JOIN دقیقاً همان خروجی را که از مثالهای INNER JOIN و JOIN USING به دست آوردیم ارائه میکند. چون که در این مثال سه کوئری برابر هستند. اما در برخی موارد ممکن است خروجی متفاوت باشد. برای نمونه اگر جداول بیشتری با نامهای یکسان وجود داشته باشند، NATURAL JOIN همه ستونها را با همدیگر تطبیق میدهد. با این حال، INNER JOIN تنها ستونهایی که در شرط JOIN مشخص شده باشد را با هم مقایسه میکند.
LEFT OUTER JOIN در SQLite
استاندارد SQL سه نوع OUTER JOIN به صورت LEFT OUTER JOIN چپ، راست و کامل تعریف کرده است. SQLite تنها از LEFT OUTER JOIN پشتیبانی میکند.
در LEFT OUTER JOIN همه مقادیر ستونی که از جدول چپ انتخاب شده است در نتیجه کوئری قرار میگیرد، از این رو صرفنظر از این که مقداری با شرط الحاق تطبیق یابد یا نیابد، در نتیجه قرار خواهد گرفت.
بنابراین اگر جدول چپ دارای n ردیف باشد، نتایج کوئری نیز n ردیف خواهند داشت. با این حال در مورد مقادیر ستونی که از جدول سمت راست میآیند، اگر هر مقداری با شرط JOIN تطبیق نیابد دارای مقدار تهی خواهد بود.
بنابراین تعداد ردیفهای نتیجه برابر با تعداد ردیفهای جدول چپ خواهد بود. به طوری که ردیفهای تطبیق یافته از هر دو جدول به علاوه ردیفهای تطبیق نیافته از جدول چپ به دست میآید.
مثال
در مثال زیر از LEFT JOIN برای Join کردن دو جدول Students و Departments استفاده میکنیم:
SELECT
Students.StudentName,
Departments.DepartmentName
FROM Students -- this is the left table
LEFT JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;در کوئری فوق ساختار LEFT JOIN همانند INNER JOIN است. ما LEFT JOIN را بین دو جدول مینویسیم و سپس شرط JOIN را پس از بند ON میآوریم.
جدول اول پس از بند FROM جدول چپ است. در حالی که جدول دوم که پس از LEFT JOIN میآید جدول راست است.
بند OUTER اختیاری است، چون LEFT OUTER JOIN همان معادل LEFT JOIN است.
خروجی کوئری فوق به صورت زیر است:
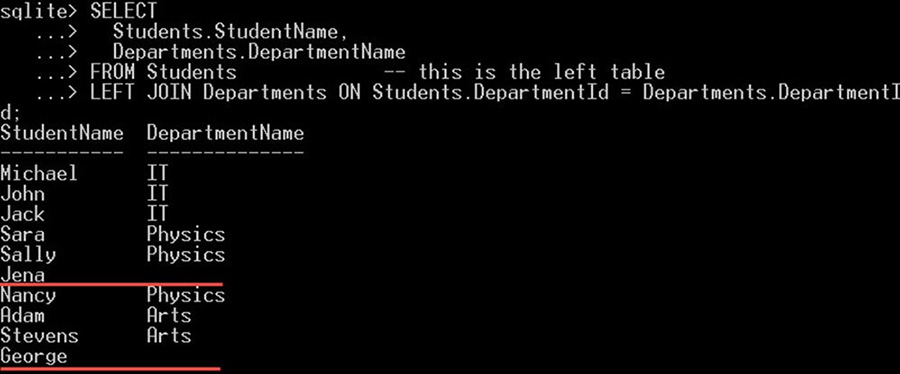
چنان که میبینید همه ردیفها از جدول دانشجویان در نتیجه حضور دارند که شامل 10 دانشجو هستند. حتی با این که دپارتمان دانشجوهای چهارم و آخر یعنی جِنا و جرج در جدول Departments وجود ندارد، اما در نتایج قرار گرفتهاند.
در این موارد مقدار departmentName برای هر دو مورد جنا و جرج به صورت NULL است زیرا جدول دپارتمانها دارای departmentName نیست تا با مقدار departmentId آنها تطبیق یابد.
در تصویر زیر نمودار ون LEFT JOIN را مشاهده میکنید.
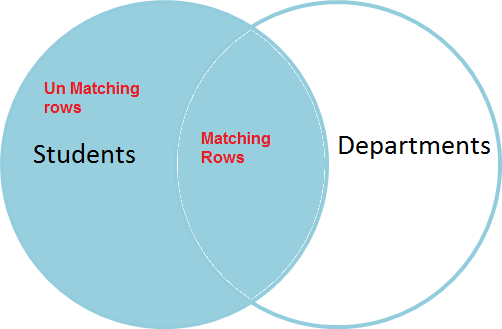
LEFT JOIN اسامی همه دانشجویان را از جدول دانشجویان ارائه میکند، هر چند دانشجویی دارای یک شناسه دپارتمان باشد که در جدول دپارتمانها وجود ندارد. بنابراین این کوئری مانند INNER JOIN تنها ردیفهای تطبیق یافته را ارائه نمیکند، بلکه بخش اضافی را که شامل ردیفهای تطبیق نیافته از جدول چپ است را نیز ارائه میکند.
توجه داشته باشید که نام دانشجویی که دپارتمانی برای آن یافت نشده دارای مقدار NULL برای نام دپارتمان است و این مقادیر در ردیفهای تطبیق نیافته است.
CROSS JOIN در SQLite
CROSS JOIN حاصلضرب دکارتی ستونهای منتخب از دو جدول Join-شده را ارائه میکند و همه مقادیری تطبیق یافته از جدول اول را با همه مقادیر جدول دوم عرضه میکند.
بنابراین برای هر مقدار در جدول اول n تطبیق از جدول دوم به دست میآید که n تعداد ردیفهای جدول دوم است.
CROSS JOIN برخلاف INNER JOIN و LEFT OUTER JOIN نیازی به تعیین شرط الحاق ندارد، زیرا SQLite برای CROSS JOIN به آن نیازمند نیست.
SQLite مجموعه نتایج منطقی را با مقایسه کردن همه مقادیر از جدول اول با همه مقادیر از جدول دوم ارائه میکند.
برای نمونه فرض کنید یک ستون از جدول اول (colA) و ستون دیگر از جدول دوم (colB) انتخاب شده باشد، cola شامل دو مقدار (1,2) و colB شامل دو مقدار (3,4) است. در این صورت نتیجه CROSS JOIN چهار ردیف خواهد بود:
- دو ردیف با ترکیب کردن مقدار نخست از cola که 1 است با دو مقدار colB که 3 و 4 هستند به دست میآید که به صورت (1,3), (1,4) است.
- به طور مشابه، دو ردیف با ترکیب کردن مقدار دوم از cola که 2 است با دو مقدار از colB یعنی (3,4) به دست میآید که نتیجه به صورت (2,3), (2,4) است.
مثال
در کوئری زیر الحاق به صورت CROSS JOIN را بین دو جدول Students و Departments بررسی میکنیم:
SELECT
Students.StudentName,
Departments.DepartmentName
FROM Students
CROSS JOIN Departments;در کوئری فوق در بند SELECT دو ستون به نامهای studentname از جدول دانشجویان و departmentName از جدول دپارتمانها انتخاب شده است.
در مورد CROSS JOIN نیاز به تعیین هیچ شرط برای JOIN وجود ندارد و دو جدول صرفاً با استفاده از عملگر CROSS JOIN در بینشان با هم الحاق یافتهاند.
خروجی کوئری فوق به صورت زیر است:
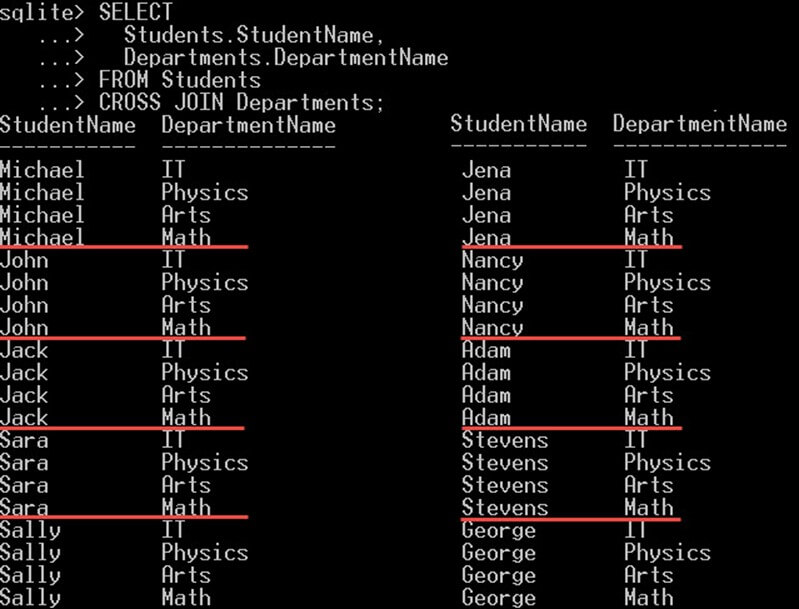
چنان که در تصویر فوق میبینید، نتیجه دارای 40 ردیف است. 10 مقدار از جدول دانشجویان آمده که با 4 دپارتمان از جدول دپارتمانها تطبیق یافتهاند. به این ترتیب:
- چهار مقدار برای چهار دپارتمان از جدول departments با دانشجوی اول به نام Michel تطبیق یافتهاند.
- چهار مقدار برای چهار دپارتمان از جدول departments با دانشجوی دوم به نام John تطبیق یافتهاند.
- چهار مقدار برای چهار دپارتمان از جدول departments با دانشجوی سوم به نام Jack تطبیق یافتهاند.
- و همین طور تا آخر.
با استفاده از JOIN-های SQLite میتوانید یک یا چند جدول را به همدیگر وصل کنید تا ستونهایی را از هر دوی جداول یا کوئریهای فرعی انتخاب کنید. در بخش بعدی این آموزش دیتابیس SQLite به بررسی روش کار با دادهها در جداول این پایگاه داده میپردازیم.
کوئریهای دستکاری دادهها در SQLite
بندهای اصلاح دادهها در SQLite شامل گزارههای INSERT, UPDATE و DELETE هستند. از این موارد برای درج ردیفهای جدید، بهروزرسانی مقادیر موجود و یا حذف ردیفها از پایگاه داده استفاده میشود.
توجه کنید که در همه مثالهای زیر باید sqlite3.exe را اجرا کرده و یک اتصال با پایگاه داده نمونه به صورت زیر برقرار سازید. به دایرکتوری C:sqlite بروید و روی sqlite3.exe دابل-کلیک کنید تا باز شود.
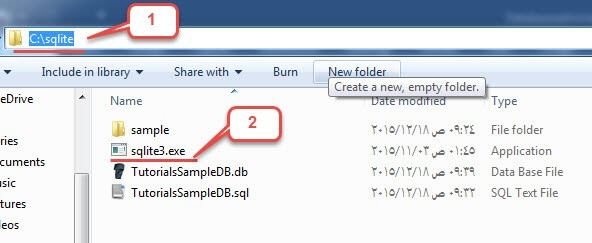
با اجرای دستور زیر پایگاه داده TutorialsSampleDB.db را باز کنید:
.open TutorialsSampleDB.db
اکنون آماده اجرای هر نوع کوئری روی این دیتابیس هستیم.
INSERT در SQLite
گزاره INSERT در SQLite برای درج رکوردها در یک جدول مشخصشده پایگاه داده مورد استفاده قرار میگیرد. ساختار INSERT به صورت زیر است:
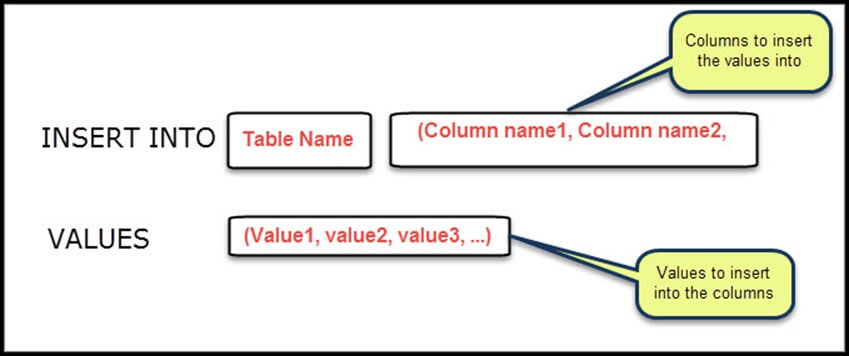
- پس از بند INSERT باید مشخص سازید که مقادیر باید در کدام جدول درج شوند.
- پس از نام جدول یک فهرست از ستونها که میخواهیم مقادیر در آنها درج شوند مینویسیم.
- میتوان نام ستونها را نادیده گرفته و آنها را ننوشت.
- اگر نام ستونها نوشته نشوند، مقادیر در همه ستونهایی در جدول یافت میشوند، به همان ترتیب که ستونها در جدول تعریف شدهاند، درج میشوند.
- پس از بند VALUES باید فهرستی از مقادیری که باید درج شوند ارائه شود.
- هر بند INSERT تنها یک ردیف به دیتابیس اضافه میکند. اگر میخواهید چندین ردیف در دیتابیس درج کنید، باید چندین بند INSERT و یک بند برای هر ردیف بنویسید.
مثالی از INSERT در SQLite
در مثال زیر 2 ردیف را در جدول دانشجویان وارد میکنیم که هر ردیف به یک دانشجو اختصاص دارد:
INSERT INTO Students(StudentId, StudentName, DepartmentId, DateOfBirth)
VALUES(11, 'Ahmad', 4, '1997-10-12');
INSERT INTO Students VALUES(12, 'Aly', 4, '1996-10-12');این کوئری باید با موفقیت اجرا شود و در این صورت هیچ خروجی نخواهد داشت:

کوئری فوق دو دانشجو در دیتابیس وارد میکند:
- دانشجوی اول با شناسه StudentId=11، با نام StudentName = Ahmad، با شناسه دپارتمان DepartmentId = 4 و با تاریخ تولد DateOfBirth = 1997-10-12 است.
- دانشجوی دوم دارای شناسه StudentId=12، نام StudentName = Aly، شناسه دپارتمان DepartmentId = 4، و تاریخ تولد DateOfBirth = 1996-10-12 است.
در گزاره اول نام ستونها را به صورت StudentId, StudentName, DepartmentId, DateOfBirth فهرستبندی کردهایم. اما در گزاره دوم این کار را انجام ندادهایم.
به این ترتیب چهار مقدار 12, Aly، 4، 1996-10-12 در چهار ستون جدول Students به همان ترتیبی که ستونها تعریف شدهاند قرار میگیرند. در ادامه با اجرای کوئری زیر از صحت درج شدن دو دانشجو در جدول Students اطمینان حاصل میکنیم.
SELECT * FROM Students;در این زمان باید دو دانشجو را که از کوئری فوق بازگشت یافتهاند به صورت زیر ببینید:
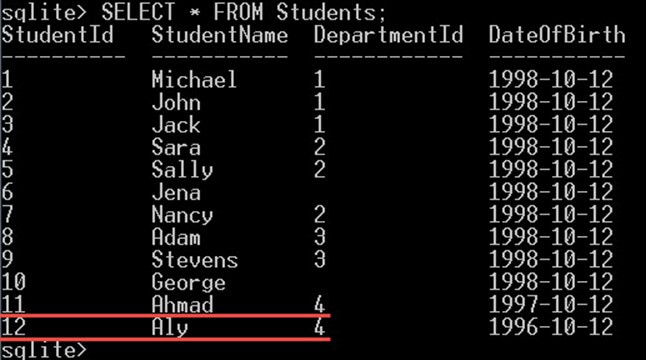
Update در SQLite
کوئری Update برای اصلاح رکوردهای موجود در یک جدول مورد استفاده قرار میگیرد. امکان استفاده از بند WHERE به همراه کوئری Update برای بهروزرسانی ردیفهای منتخب وجود دارد. بند Update یک جدول را با تغییر دادن مقدار یک ستون خاص بهروزرسانی میکند. در ادامه ساختار بند Update را میبینید:
- به این ترتیب پس از update clause باید نام جدولی که باید بهروز شود را بنویسید.
- از SET برای نوشتن نام ستونی که باید بهروز شود و مقداری که باید تغییر یابد استفاده میکنیم.
- امکان بهروزرسانی بیش از یک ستون وجود دارد. میتوانید از یک کاما بین هر خط استفاده کنید.
- امکان استفاده از بند WHERE برای تعیین کردن برخی ردیفهای خاص وجود دارد. به این ترتیب تنها ردیفهایی که عبارت مورد نظر برای آنها به صورت true ارزیابی شود، بهروزرسانی میشوند. اگر بند WHERE تعیین نشده باشد، همه ردیفها بهروز میشوند.
مثالی از UPDATE در SQLite
در گزاره UPDATE زیر مقدار DepartmentId برای دانشجویی با شناسه StudentId به مقدار 6 به مقدار 3 تغییر مییابد:
UPDATE Students
SET DepartmentId = 3
WHERE StudentId = 6;اگر این کوئری با موفقیت اجرا شود هیچ خروجی دریافت نخواهد شد:
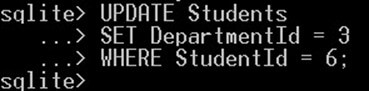
در بند UPDATE تعیین کردهایم که میخواهیم جدول Students بهروزرسانی شود.
- در بند WHERE همه دانشجویان را فیلتر کردهایم تا تنها ردیفی که شرط StudentId = 6 در مورد آن برقرار است انتخاب و بهروزرسانی شود.
- بند SET مقدار Department Id را برای دانشجوی منتخب به عدد 3 تغییر میدهد.
اینک بررسی میکنیم آیا شناسه این دانشجوی با عدد 6 تغییر یافته است یا نه:
SELECT * FROM Students WHERE StudentId = 6;اکنون میبینیم که شناسه دپارتمان این دانشجو از 6 به 3 عوض شده است:

DELETE در SQLite
کوئری DELETE در SQLite برای حذف رکوردهای موجود از جدول مشخصشده استفاده میشود. امکان استفاده از بند WHERE به همراه کوئریهای DELETE برای حذف ردیفهای منتخب نیز وجود دارد. بند DELETE دارای ساختار زیر است:
شما باید نام جدولی که میخواهید رکوردهایش را حذف کنید، پس از بند DELETE FROM بنویسید. توجه کنید که بند DELETE برای حذف برخی رکوردها از جدول یا حذف همه رکوردهای آن استفاده میشود و در هر حال موجب حذف خود جدول نمیشود. برای حذف خود جدول باید از بند DROP استفاده کنید که جدول را به همراه همه رکوردهایش به طور کامل حذف میکند.
اگر بند DELETE را به صورت DELETE FROM xyz بنویسید، این کوئری موجب حذف رکوردها از جدول xyz خواهد شد.
در صورتی که بخواهید برخی ردیفهای خاص را پاک کنید، امکان تعیین شرط WHERE با یک عبارت نیز وجود دارد. در این صورت تنها ردیفهایی که مقدار عبارت برای آنها به صورت true ارزیابی شود پاک میشوند. برای نمونه DELETE FROM xyz WHERE id > 5 موجب میشود که تنها رکوردهایی که شناسه بزرگتر از 5 دارند حذف شوند.
مثال
در گزاره زیر ما دو دانشجو را با شناسههای دانشجویی 11 و 12 حذف میکنیم:
DELETE FROM Students WHERE StudentId = 11 OR StudentId = 12;عبارت StudentId = 11 OR StudentId = 12 تنها برای دانشجویانی با شناسه 11 و 12 درست خواهد بود و از این رو بند DELETE روی این دو اعمال شده و تنها آنها را حذف میکند.
این دستور با موفقیت اجرا میشود و به این ترتیب هیچ خروجی تولید نخواهد کرد:

با اجرای کوئری زیر میتوانید از صحت اجرای کوئری فوق اطمینان حاصل کنید:
SELECT * FROM Students;به این ترتیب دیگر دو دانشجوی با شناسههای 11 و 12 را نمیبینیم:

Conflict در SQLite
فرض کنید ستونی دارید که یکی از قیود ستون UNIQUE, NOT NULL, CHECK یا PRIMARY KEY را دارد. اگر تلاش کنید مقداری را روی این ستون درج یا بهروزرسانی کنید که با مقداری که این قید دارد در تعارض باشد، با مشکل مواجه خواهید شد.
برای نمونه اگر یک ستون دارای قید UNIQUE باشد و تلاش کنید مقداری را که از قبل موجود است در آن درج کنید با قید UNIQUE تعارض مییابد. در این حالت بند CONFLICT به شما امکان میدهد که کارهای مختلفی را که برای حل این تعارض میتوان انجام داد انتخاب کنید.
پیش از آن که به ادامه توضیح شیوه حل تعارض از سوی CONFLICT آشنا شویم، باید با مفهوم «تراکنش» (Transaction) در پایگاه داده آشنا باشیم.
تراکنش پایگاه داده
اصطلاح تراکنش دیتابیس به فهرستی از عملیات SQLite (شامل درج، بهروزرسانی یا حذف) گفته میشود. تراکنش پایگاه داده باید در یک واحد اجرا شود و یا همه عملیات با موفقیت اجرا میشود و یا هیچ کدام موفق نخواهند بود. در این حالت در صورت شکست یکی از موارد، همه عملیات لغو میشود.
مثالی از یک تراکنش پایگاه داده
تراکنش انتقال پول از یک حساب بانکی به حساب دیگر شامل چند فعالیت است. این عملیات تراکنش شامل برداشتن پول از یک حساب و گذاشتن در حساب دیگر است. این تراکنش باید یا به طور کامل انجام یابد و با در صورتی که نصف آن موفق و نصف دیگر ناموفق باشد، کلاً لغو شود.
در ادامه فهرستی از پنج راهکار که میتوانید در بند CONFLICT انتخاب کنید را ارائه میکنیم:
- ROLLBACK – این گزینه موجب میشود که تراکنشی که گزاره جاری SQLite در آن دچار تعارض شده است، به حالت قبل بازگردد، یعنی کل تراکنش لغو شود. برای نمونه اگر تلاش کردهاید 10 ردیف را بهروزرسانی کنید و ردیف پنجم دارای مقداری در تضاد با یک قید بوده است، در این صورت هیچ ردیفی بهروزرسانی نمیشود و هر 10 ردیف به حالت قبل خود باقی میمانند. در این زمان یک نیز خطا صادر میشود.
- ABORT – این گزینه موجب خروج (لغو) آن گزاره جاری SQLite که موجب تعارض گشته است میشود. برای نمونه اگر تلاش کنید 10 ردیف را بهروزرسانی کنید و ردیف پنجم دارای مقداری باشد که با یک قید در تضاد است، در این صورت تنها مقدار پنجم بهروزرسانی نمیشود و بقیه ردیفها بهروزرسانی خواهند شد. در این حالت نیز خطایی صادر میشود.
- FAIL – گزاره جاری SQLite را که موجب تعارض شده لغو میکند. با این که تراکنش تداوم نمییابد، اما تغییرات قبلی که روی ردیفهای قبلی صورت گرفتهاند، اعمال میشوند. برای نمونه اگر تلاش کنید 10 ردیف را بهروزرسانی کنید و ردیف پنجم دچار تعارض با یک قید شود، تنها 4 ردیف اول بهروزرسانی میشوند و بقیه موارد به حال خود باقی میمانند. در این حالت نیز خطایی صادر میشود.
- IGNORE – این گزینه موجب میشود که ردیف دچار تعارض، نادیده گرفته شود و فرایند کار روی ردیفهای دیگر گزاره SQLite ادامه مییابد. برای نمونه اگر تلاش کنید 10 ردیف را بهروزرسانی کنید، در این صورت تنها 4 ردیف بهروزرسانی میشوند و با نادیده گرفتن ردیف پنجم، بقیه ردیفها به صورت معمول بهروزرسانی میشوند. در این حالت هیچ خطایی صادر نمیشود.
- REPLACE – این گزینه به نوع قیدی که از آن تخطی شده است بستگی دارد. شرح موارد به صورت زیر است:
زمانی که قید مورد تخطی به صورت UNIQUE یا PRIMARY KEY باشد، گزینه REPLACE ردیفی که موجب این تعارض شده را با ردیف جدیدی که درج و بهروزرسانی میکند جایگزین مینماید.
زمانی که از یک قید NOT NULL تخطی شده باشد، بند REPLACE همه مقادیر NULL را با مقدار پیشفرض آن ستون جایگزین میکند. اگر ستون مقدار پیشفرض نداشته باشد در این صورت QLite از گزاره خارج میشود یعنی گزاره لغو میشود.
اگر از قید CHECK تخطی شده باشد، در این صورت اجرای گزاره لغو میشود.
نکته: 5 راهکار فوق گزینههایی برای روش حل تعارض محسوب میشوند. اینها ممکن است لزوماً آن چیزی نباشند که برای حل یک تعارض خاص مورد استفاده قرار میگیرند.
اعلان بند CONFICT
امکان اعلان بند ON CONFLICT در مواردی که به تعریف قید یک ستون میپردازید، درون بند CREATE TABLE وجود دارد. ساختار کار به صورت زیر است:
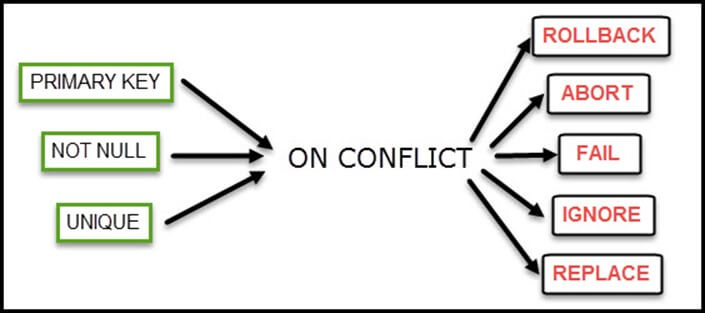
امکان انتخاب یکی از پنج راهکار برای حل تعارضی که پیشتر توضیح دادیم وجود دارد.
مثالی از ON CONFLICT IGNORE
ابتدا یک جدول subject جدید به صورت زیر ایجاد کنید:
CREATE TABLE [Subjects] (
[SubjectId] INTEGER NOT NULL PRIMARY KEY ON CONFLICT IGNORE,
[SubjectName] NVARCHAR NOT NULL
);توجه کنید که قید PRIMARY KEY روی ستون SubjectId تعریف شده است. قید کلید اصلی یا PRIMARY KEY امکان درج مقادیر تکراری در ستون SubjectId را نمیدهد و همه مقادیر این ستون باید یکتا باشند. ضمناً توجه کنید که نوع حل تعارض را نیز به صورت IGNORE انتخاب کردهایم. این دستور باید با موفقیت اجرا شود و از این رو هیچ خطایی دریافت نمیکنیم:

در ادامه برخی مقادیر را در جدول جدید موضوعها درج میکنیم، اما مقداری که میخواهیم وارد کنیم از قید کلید اصلی تخطی میکنند:
INSERT INTO Subjects VALUES(1, 'Algebra');
INSERT INTO Subjects VALUES(2, 'Database Course');
INSERT INTO Subjects VALUES(2, 'Data Structures');
INSERT INTO Subjects VALUES(4, 'Algorithms');در این گزارههای INSERT تلاش کردهایم د و دوره درسی با کلید اصلی یکسان 2 وارد کنیم که یک تخطی از قید primary key محسوب میشود. این دستورها باید با موفقیت اجرا شوند و خطایی دریافت نشود:

در این بخش همه موضوعهای جدول را به صورت زیر انتخاب میکنیم:
SELECT * FROM Subjects;به این ترتیب فهرست موضوعهای زیر در خروجی به دست میآید:
دقت کنید که به جای 2 موضوعی که تلاش کرده بودیم درج کنیم، تنها سه سوژه Algebra, Database Course و Algorithms درج شدهاند. ردیفی که دارای مقداری است که از قید کلید اصلی تخطی کرده یعنی Data Structures نادیده گرفته شده است و درج نشده است. با این حال SQLite به کار خود ادامه داده و گزارههای بعد از آن را در جدول درج کرده است.
در این بخش سوژههای جدول را حذف میکنیم تا آنها را دوباره با بند ON CONFLICT مختلفی وارد کنیم:
DROP TABLE Subjects;دستور DROP کل جدل را حذف میکند. اینک جدول Subjects دیگر وجود ندارد.
مثالی از ON CONFLICT REPLACE
ابتدا یک جدول sunhects به صورت زیر ایجاد میکنیم:
CREATE TABLE [Subjects] (
[SubjectId] INTEGER NOT NULL PRIMARY KEY ON CONFLICT REPLACE,
[SubjectName] NVARCHAR NOT NULL
);توجه کنید که قید PRIMARY KEY را روی ستون SubjectId تعریف کردهایم. قید کلید اصلی به ما اجازه نمیدهد که مقادیر تکراری را در ستون SubjectId وارد کنیم، به طوری که مقادیر در ستون باید یکتا باشند.
ضمناً توجه کنید که گزینه حل تعارض به صورت REPLACE تعیین شده است. این دستور باید با موفقیت اجرا شود و هیچ خطایی دریافت نشود:

اینک برخی مقادیر را در جدول جدید subjects وارد میکنیم، اما این بار مقدار آن از قید کلید اصلی تخطی میکند:
INSERT INTO Subjects VALUES(1, 'Algebra');
INSERT INTO Subjects VALUES(2, 'Database Course');
INSERT INTO Subjects VALUES(2, 'Data Structures')
INSERT INTO Subjects VALUES(4, 'Algorithms');در این گزارههای INSERT تلاش کردهایم تا دو دوره آموزشی با کلید اصلی یکسان برای شناسه سوژه به مقدار 2 وارد کنیم. این دستورها باید با موفقیت اجرا شوند و هیچ خطابی دریافت نکنیم:
در این بخش همه سوژهها را از جدول subjects با کوئری زیر انتخاب میکنیم:
SELECT * FROM Subjects;کوئری فوق فهرست سوژههای زیر را ایجاد میکند:
توجه کنید که علیرغم تلاش ما برای درج 4 سوژه، سه سوژه به صورت Algebra, Data Structures, و Algorithms درج شدهاند. ردیفی که شامل مقدار متعارض با قید کلید اصلی است، یعنی Data Structures با مقدار Database Course به شرح زیر جایگزین شده است:
- دو گزاره نخست درج بدون هیچ مشکلی با موفقیت اجرا شدهاند. دو سوژه Algebra و Database Course با شناسههای 1 و 2 درج شدهاند.
- زمانی که SQLite تلاش میکند که گزاره درج سوم را با شناسه 2 و نام Data Structures وارد کند یک تخطی از قید کلید اصلی که در ستون SubjectId تعریف شده است، رخ میدهد.
- SQLite راهکار REPLACE را برای این تعارض انتخاب میکند. بدین ترتیب مقداری که از قبل در جدول subjectys وجود داشت با مقدار جدید از گزاره insert جایگزین میشود. بنابراین نام درس Database Course با مقدار Data Structures عوض خواهد شد.
در این بخش از آموزش دیتابیس SQLite با بندهای INSERT, UPDATE و DELETE برای تغییر دادن دادههای موجود در پایگاههای داده SQLite آشنا شدیم. بند CONFLICT یک بند قدرتمند برای حل مشکل تعارض بین دادههای موجود و دادههای جدیدی که قرار است درج شوند محسوب میشود.
معرفی Index ،Trigger و View با مثال
در کاربردهای روزمره SQLite به برخی ابزارهای مدیریتی برای کار با پایگاههای داده نیاز داریم. از این ابزارها میتوان برای کوئری زدن به دیتابیس به روش کارآمدتر با ساخت اندیس بهره گرفت و یا با ساخت نماها امکان استفاده مجدد از کوئریها را افزایش داد.
نما در SQlite
نماها (Views) بسیار مشابه جدولها هستند. اما نماها جداول منطقی هستند و به صورت فیزیکی مانند جدولها ذخیره نمیشوند. یک نما از یک گزاره SELECT تشکیل مییابد. امکان تعریف یک نما برای کوئریهای پیچیده وجود دارد و میتوان از این کوئریها در ادامه هر زمان که بخواهیم نما را مستقیماً فراخوانی کنیم به جای نوشتن مجدد کوئریها استفاده کنیم.
گزاره CREATE VIEW
برای ایجاد یک نما روی یک پایگاه داده میتوانید از گزاره CREATE VIEW به همراه نام نما استفاده کنید و سپس کوئری را که میخواهید پس از آن قرار دهید.
مثال
در مثال زیر یک نما با نام AllStudentsView در دیتابیس نمونه TutorialsSampleDB.db ایجاد میکنیم. ابتدا My Computer را بازکرده و به مسیر دایرکتوری C:sqlite بروید و روی sqlite3.exe دابل-کلیک کنید.
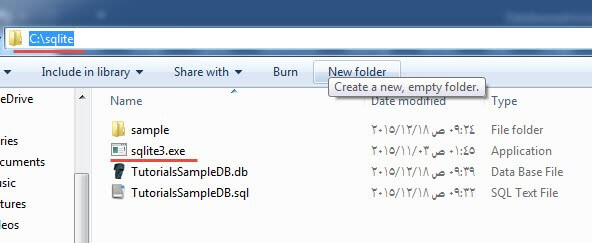
پایگاه داده TutorialsSampleDB.db را با فراخوانی دستور زیر باز کنید:
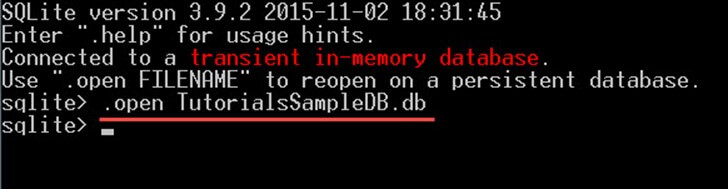
در ادامه ساختار ابتدایی دستور sqlite3 برای ایجاد نما را میبینید:
CREATE VIEW AllStudentsView
AS
SELECT
s.StudentId,
s.StudentName,
s.DateOfBirth,
d.DepartmentName
FROM Students AS s
INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;این دستور در صورت اجرای موفق، باید هیچ خروجی نداشته باشد:
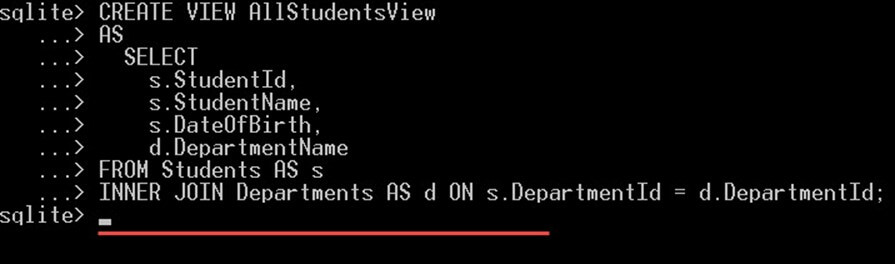
برای اطمینان یافتن از این که نما ایجاد شده است، میتوانید فهرست نماها را در پایگاه داده با اجرای دستور زیر انتخاب کنید:
SELECT name FROM sqlite_master WHERE type = 'view';اینک میتوانید نمای AllStudentsView که بازگشت یافته است را ببینید:

اکنون که نما ایجاد شده است، میتوانید از آن به صورت جدول نرمال مانند زیر استفاده کنید:
SELECT * FROM AllStudentsView;این دستور به نمای AllStudents کوئری میزند و مانند تصاویر زیر همه ردیفها را انتخاب میکند:
نماهای موقت
نماهای موقت صرفاً در بازه اتصال به پایگاه داده ایجاد میشوند. در این صورت اگر اتصال به پایگاه داده بسته شود، همه نماهای موقت به صورت خودکار حذف میشوند. نماهای موقت با استفاده از یکی از دستورهای زیر ایجاد میشوند:
- CREATE TEMP VIEW
- CREATE TEMPORARY VIEW
در صورتی که بخواهید برخی عملیات را برای مدت معینی اجرا کنید و در ادامه به آنها نیاز نخواهید داشت بهتر است از نماهای موقت استفاده کنید. به این ترتیب صرفاً یک نمای موقت ایجاد میشود و میتوانید کارهای خود را با آن نما انجام دهید. در ادامه زمانی که اتصال به دیتابیس بسته شود، این نمای موقت به صورت خودکار حذف خواهد شد.
مثال
در مثال زیر یک اتصال به دیتابیس باز میکنیم و سپس یک نمای موقت ایجاد خواهیم کرد. سپس این اتصال را میبندیم و بررسی میکنیم آیا نماهای موقت همچنان وجود دارند یا نه.
ابتدا فایل sqlite3.exe را از مسیر C:sqlite باز کنید. سپس با اجرای دستور زیر یک اتصال به دیتابیس TutorialsSampleDB.db ایجاد نمایید:
.open TutorialsSampleDB.dbدستور زیر را برای ایجاد یک نمای موقت به نام AllStudentsTempView اجرا کنید:
CREATE TEMP VIEW AllStudentsTempView
AS
SELECT
s.StudentId,
s.StudentName,
s.DateOfBirth,
d.DepartmentName
FROM Students AS s
INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
با اجرای دستور زیر مطمئن شوید که نمای موقت AllStudentsTempView ایجاد شده است:
SELECT name FROM sqlite_temp_master WHERE type = 'view';
sqlite3.exe را بسته و دوباره باز کنید. با اجرای دستور زیر یک اتصال به پایگاه داده TutorialsSampleDB.db ایجاد کنید:
.open TutorialsSampleDB.dbدستور زیر را اجرا کنید تا فهرستی از نماهای موقت که روی دیتابیس ایجاد شده به دست آورید:
SELECT name FROM sqlite_temp_master WHERE type = 'view';از آن جا که در گام قبلی نمای موقت ایجاد شده پس از بسته شدن اتصال به پایگاه داده حذف شده است، هیچ چیزی در خروجی دیده نمیشود. در غیر این صورت تا زمانی که اتصال به دیتابیس برقرار باشد، میتوانید نمای موقت را با دادههایش ببینید.

امکان استفاده از گزارههای INSERT, DELETE یا UPDATE روی نماها وجود ندارد و تنها میتوان از دستور select from views استفاده کرد. برای حذف یک نما میتوانید از گزاره DROP VIEW استفاده کنید:
DROP VIEW AllStudentsView;برای اطمینان یافتن از این که نما حذف شده است، میتوانید دستور زیر ا اجرا کنید که فهرستی از نماهای موجود در دیتابیس را ارائه میکند:
SELECT name FROM sqlite_master WHERE type = 'view';بدین ترتیب میبینیم که هیچ نمایی بازگشت نمییابد، زیرا نما حذف شده است:

Index در SQlite
اگر یک کتاب داشته باشیم و بخواهیم به دنبال یک کلیدواژه در کتاب بگردیم، باید در اندیس کتاب جستجو کنیم. به این ترتیب به صفحهای که کلیدواژه در آن قرار دارد میرسیم و اطلاعاتی در مورد کلیدواژه مورد نظر خود به دست میآوریم. اما اگر هیچ اندیس یا شماره صفحهای در کتاب نباشد، باید کل کتاب را از ابتدا تا انتها اسکن کنید تا کلیدواژهای را که به دنبالش هستید پیدا کنید. این کار دشواری است و به طور خاص در مواردی که کار جستجو کند باشد وقت زیادی از شما میگیرد.
اندیسها در SQLite و دیگر سیستمهای مدیریت دیتابیس به روشی مشابه اندیسهای انتهای کتابها عمل میکنند.
زمانی که به دنبال برخی ردیفها در یک جدول SQLite با یک معیار جستجو هستید، SQLIte روی همه ردیفها جستجو میکند تا آن چیزی که به دنبالش هستید را پیدا کند. زمانی که جدول بزرگ باشد این فرایند بسیار کند خواهد بود.
اندیسها موجب افزایش سرعت اجرای کوئری روی دادهها میشوند و به بازیابی دادهها از جداول کمک میکنند. اندیسها روی ستونهای جداول تعریف میشوند.
بهبود عملکرد با اندیسها
اندیسها موجب افزایش عملکرد جستجوی دادهها روی جدول میشوند، زمانی که یک اندیس را روی یک ستون ایجاد میکنید، SQLite یک ساختمان داده برای آن اندیس ایجاد میکند که در آن مقدار هر فیلد یک اشارهگر به کل ردیفی که مقدار به آن تعلق دارد ارائه میکند.
در ادامه زمانی که یک کوئری با شرط جستجو روی ستونی که بخشی از یک اندیس است، اجرا کنید، SQLite ابتدا به دنبال مقداری روی خود اندیس میگردد. به این ترتیب SQLite کل جدول را برای یافتن آن مقدار اسکن نمیکند. بلکه مکانی که آن مقدار روی ردیف جدول به آن اشاره دارد را میخواند. SQLite ردیفی که در آن مکان قرار دارد را یافته و مقدارش را بازیابی میکند.
با این حال، اگر ستونی که به دنبالش هستید، بخشی از یک اندیس باشد، SQLite یک اسکن برای مقادیر ستون اجرا میکند تا دادههایی که به دنبالش هستید را پیدا کند. در صورت عدم وجود اندیس، جستجو به طور معمول کندتر خواهد بود.
کتابی را تصور کنید که هیچ اندیسی ندارد و باید به دنبال یک کلید خاص بگردید. به این ترتیب باید از صفحه ابتدا تا آخر کتاب را به دنبال آن کلمه بگردید. اما اگر این کتاب اندیسی در انتهای خود داشته باشد میتوانید شماره صفحه کلمه مربوطه را یافته و مستقیماً به آن صفحه بروید. بدیهی است این روش بسیار سریع تراز گشتن در کل کتاب خواهد بود.
CREATE INDEX در SQLite
برای ایجاد یک اندیس روی یک ستون باید از دستور CREATE INDEX استفاده کنید. روش تعریف آن به صورت زیر است:
- باید نام اندیس را پس از دستور CREATE INDEX تعیین کنید.
- پس از نام اندیس باید کلیدواژه ON را بیاورید و سپس نام جدولی را که اندیس در آن ایجاد خواهد شد بیاورید.
- در ادامه فهرست نامهای ستون که برای اندیس استفاده میشود را میآوریم.
- امکان استفاده از کلیدواژههای ASC و DESC پس از هر نام ستون برای تعیین ترتیب مرتبسازی دادههای اندیسشده نیز وجود دارد.
مثال
در مثال زیر، یک اندیس به نام StudentNameIndex روی جدول دانشجویان در پایگاه داده Students به صورت زیر ایجاد میکنیم:
ابتدا به پوشه C:sqlite بروید و روی فایل sqlite3.exe دابل-کلیک کنید. سپس دیتابیس TutorialsSampleDB.db را با دستور زیر باز کنید:
.open TutorialsSampleDB.dbاندیس جدید StudentNameIndex را با دستور زیر ایجاد میکنیم:
CREATE INDEX StudentNameIndex ON Students(StudentName);بدین ترتیب هیچ خروجی نمیبینید:

برای اطمینان یافتن از این که اندیس اجرا شده است، میتوانید کوئری زیر را اجرا کنید که فهرستی از اندیسها در جدول دانشجویان به دست میدهد:
PRAGMA index_list(Students);چنان که میبینید هیچ ایندکسی ایجاد نشده است:
اندیسها نه تنها میتوانند بر اساس ستونها، بلکه بر اساس عبارتها نیز مانند مثال زیر ایجاد میشوند:
CREATE INDEX OrderTotalIndex ON OrderItems(OrderId, Quantity*Price);OrderTotalIndex بر اساس ستون OrderId است و همچنین برابر با حاصلضرب ستون Quantity و مقدار ستون Price است. بنابراین هر کوئری برای OrderId و Quantity*Price به دلیل استفاده از کوئری، بهینه خواهد بود.
اگر یک بند WHERE در گزاره CREATE INDEX تعیین شده باشد، اندیس به صورت اندیس جزئی خواهد بود. در این حالت، مدخلهایی در اندیس برای صرفاً آن ردیفهایی که در بند WHERE قرار دارند وجود خواهد داشت. برای نمونه به اندیس زیر توجه کنید:
CREATE INDEX OrderTotalIndexForLargeQuantities ON OrderItems(OrderId, Quantity*Price)
WHERE Quantity > 10000;در مثال فوق، اندیس یک اندیس جزئی است، چون بند WHERE تعیین شده است. در این حالت اندیس صرفاً روی آن سفارشهایی (Orders) اعمال میشود که مقدار کمیت آنها بیش از 1000 باشد. توجه کنید که اندیس به این جهت اندیس جزوی نامیده میشود که بند WHERE وجود دارد و نه چون در آن از عبارت استفاده شده است. با این حال میتوانید از عبارتها نیز در اندیسهای نرمال استفاده کنید.
امکان استفاده از گزاره CREATE UNIQUE INDEX به جای CREATE INDEX برای جلوگیری از مدخلهای تکراری برای ستونها وجود دارد و از این رو همه مقادیر برای توسن اندیسشده یکتا خواهند بود.
برای حذف یک اندیس باید از دستور DROP INDEX استفاده کرده و سپس نام اندیسی که باید حذف شود را بیاورید.
Trigger در SQLite
Trigger-ها عملیات خودکار از پیش تعریف شده هستند که وقتی یک اکشن خاص روی یک جدول دیتابیس رخ میدهد اجرا میشوند. یک Trigger میتواند طوری تعریف شود که هر بار یکی از اکشنهای زیر روی جدول رخ داد اجرا شود:
- INSERT کردن یک مقدار در جدول.
- DELETE کردن ردیفهای جدول.
- UPDATE کردن یکی از ستونهای جدول.
SQlite از تریگر FOR EACH ROW پشتیبانی میکند، به این ترتیب عملیات از پیش تعریف شده در تریگر برای همه ردیفهایی که در اکشنهای رخ داده روی جدول تعریف شدهاند اجرا خواهد شد.
تریگر CREATE در SQLite
برای ایجاد یک TRIGGER جدید، میتوانید از گزاره CREATE TRIGGER به صورت زیر استفاده کنید:
- پس از CREATE TRIGGER باید یک نام تریگر تعیین کنید. پس از نام تریگر زمانی که تریگر دقیقاً باید اجرا شود را تعیین میکنیم. به این منظور سه گزینه در اختیار داریم:
- BEFORE – در این حالت تریگر پیش از گزارههای INSERT, UPDATE یا delete اجرا خواهد شد.
- AFTER – در این حالت تریگر پس از گزارههای INSERT, UPDATE یا delete تعیین شده اجرا خواهد شد.
- INSTEAD OF – این گزینه جایگزین اکشنی میشود که تریگر را اجرا کرده است. استفاده از INSTEAD OF تریگر روی جدولها ممکن نیست و تنها روی نماها اعمال میشود.
- در ادامه باید نوع اکشن را تعیین کنید که میتواند یکی از گزینههای DELETE, INSERT یا UPDATE باشد.
- امکان انتخاب نام ستون اختیاری وجود دارد، به طوری که تریگر تا زمانی که اکشنی روی ستون رخ دهد اجرا نمیشود.
- در ادامه میتوانید نام جدولی را که تریگر در آن ایجاد خواهد شد تعیین کنید.
- درون بدنه تریگر باید گزارهای که باید روی هر ردیف اجرا شود تعیین کنید.
تریگرها تنها بسته به نوع گزارهای که در دستور ایجاد تریگر تعیین شده است، اجرا میشوند. برای نمونه:
- تریگر BEFORE INSERT پیش از هر گزاره INSERT فعال میشود.
- تریگر AFTER UPDATE پس از هر گزاره UPDATE فعال میشود.
درون تریگر میتوانید به مقادیر جدیداً ایجاد شده با استفاده از کلیدواژه new اشاره کنید. ضمناً میتوانید مقادیر را با استفاده از کلیدواژه قدیمی حذف یا بهروزرسانی کنید. ترتیب کار چنین است:
- درون تریگرهای INSERT کلیدواژه جدید میتواند استفاده میشود.
- درون تریگرهای UPDATE کلیدواژه جدید و قدیم میتواند استفاده شود.
- درون تریگرهای DELETE کلیدواژه قدیمی میتواند استفاده شود.
مثال
در مثال زیر یک تریگر ایجاد میکنیم که پیش از درج یک دانشجوی جدید در جدول Students ایجاد خواهد شد. بدین ترتیب دانشجوی جدیداً ایجاد شده در جدول StudentsLog با یک نشانگر زمانی خودکار لاگ میشود. مراحل کار چنین است:
به دایرکتوری C:sqlite رفته و روی فایل sqlite3.exe دابل-کلیک کنید. با اجرای دستور زیر پایگاه داده TutorialsSampleDB.db را باز کنید:
.open TutorialsSampleDB.dbبا اجرای دستور زیر تریگری به نام InsertIntoStudentTrigger ایجاد کنید:
CREATE TRIGGER InsertIntoStudentTrigger
BEFORE INSERT ON Students
BEGIN
INSERT INTO StudentsLog VALUES(new.StudentId, datetime(), 'Insert');
END;تابع ()datetime تاریخ و زمان جاری را که در زمان Insert رخ داده به دست میدهد. بنابراین میتوانیم تراکنش insert را با نشانگرهای زمانی خودکار که به هر تراکنش اضافه میشوند لاگ کنیم. اگر دستور با موفقیت اجرا شود، هیچ خروجی مشاهده نخواهد شد:
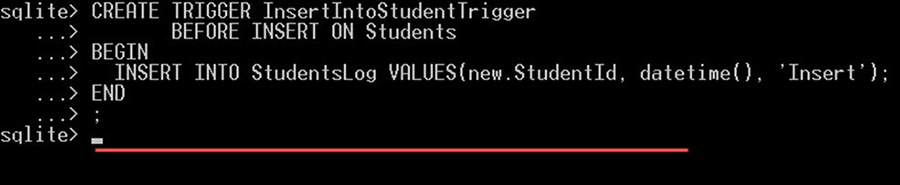
تریگر InsertIntoStudentTrigger هر بار که یک دانشجوی جدید در جدول students درج شود فعال خواهد شد. کلیدواژه new به مقادیری اشاره دارد که درج میشوند. برای نمونه new.StudentId شناسه دانشجویی است که درج خواهد شد.
در ادامه رفتار تریگر را در زمان درج دانشجوی جدید بررسی میکنیم.
ابتدا دستور زیر را بنویسید تا یک دانشجوی جدید در جدول دانشجویان درج شود:
INSERT INTO Students VALUES(11, 'guru11', 1, '1999-10-12');دستور زیر ا بنویسد تا همه ردیفهای جدول StudentsLog انتخاب شود:
SELECT * FROM StudentsLog;اینک باید ردیف مربوط به دانشجوی جدید که درج شده است را مشاهده کنید:

این ردیف پیش از درج دانشجوی با شناسه 11 به وسیله تریگر ایجاد شده است.
در این مثال از تریگر InsertIntoStudentTrigger که ایجاد کردیم استفاده شده است تا هر تراکنش درج، در جدول StudentsLog به صورت خودکار لاگ شود. به همین روش میتوانید گزارههای update یا delete را نیز لاگ کنید.
جلوگیری از بهروزرسانیهای ناخواسته با استفاده از تریگر
با استفاده از تریگرهای BEFORE UPDATE روی یک جدول، میتوان از اجرای گزارههای بهروزرسانی روی یک ستون بر اساس یک عبارت جلوگیری کرد.
مثال
در مثال زیر از اجرای هر نوع گزاره UPDATE روی ستون studentname در جدول Students جلوگیری میکنیم.
ابتدا به دایرکتوری C:sqlite رفته و فایل sqlite3.exe را اجرا کنید. سپس دیتابیس TutorialsSampleDB.db را با اجرای دستور زیر باز کنید:
.open TutorialsSampleDB.dbدر ادامه با اجرای دستور زیر یک تریگر جدید با نام preventUpdateStudentName روی جدول Students ایجاد کنید.
CREATE TRIGGER preventUpdateStudentName
BEFORE UPDATE OF StudentName ON Students
FOR EACH ROW
BEGIN
SELECT RAISE(ABORT, 'You cannot update studentname');
END;دستور RAISE یک خطا با پیام You cannot update studentname ایجاد میکند و سپس از اجرا شدن گزاره بهروزرسانی ممانعت به عمل میآورد.
اکنون کارکرد صحیح تریگر و ممانعت از بهروز شدن ستون studentname را بررسی میکنیم.
دستور زیر را که نام دانشجوی Jack را به Jack1 تغییر میدهد اجرا کنید:
UPDATE Students SET StudentName = 'Jack1' WHERE StudentName = 'Jack';به این ترتیب باید با پیام خطایی که در تریگر تعیین شده است مواجه شوید:

دستور زیر را اجرا کنید تا فهرستی از نامهای دانشجویان از جدول students انتخاب شود:
SELECT StudentName FROM Students;اینک باید نام دانشجوی JACK را که همچنان بدون تغییر مانده است ببینید:
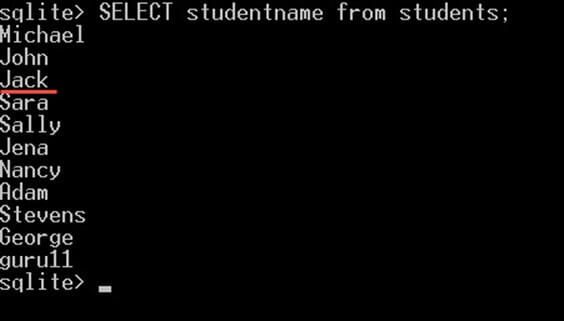
نماها، اندیسها و تریگرها ابزارهای بسیار قدرتمندی برای مدیریت پایگاههای داده SQLite محسوب میشوند. با استفاده از این ابزارها میتوانید فرایند تغییر یافتن دادهها را در زمان وقوع روی جدول ردگیری کنید. همچنین میتوانید عملیات بازیابی دادهها از جدول را با ایجاد اندیس بهینهسازی کنید.
تابعهای رشتهای SQLite
SQLite دارای برخی تابعهای داخلی برای کار با رشتهها است. همچنین امکان ایجاد تابعهای سفارشی دیگر با استفاده از زبان برنامهنویسی C نیز وجود دارد. در این بخش از مقاله آموزش دیتابیس SQLite به بررسی تابعهای رشتهای REPLACE ،SUBSTR ،TRIM و ROUND به همراه مثال میپردازیم.
توجه کنید که در همه مثالهایی که در ادامه آمده است باید برنامه sqlite3.exe را اجرا کرده و به صورت زیر یک اتصال به پایگاه داده برقرار سازید. ابتدا My Computer را باز کرده و به مسیر دایرکتوری C:sqlite بروید و سپس روی فایل sqlite3.exe دابل-کلیک کنید.
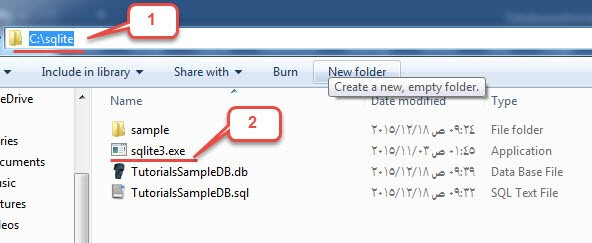
با اجرای دستور زیر پایگاه داده TutorialsSampleDB.db را که در بخشهای آغازین این راهنما ایجاد کردهایم باز کنید:
.open TutorialsSampleDB.db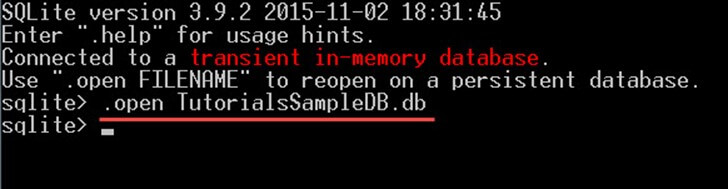
اکنون میتوانید هر نوع کوئری را روی این دیتابیس اجرا کنید.
یافتن طول یک رشته
برای یافتن طول یک رشته میتوانیم از تابع LENGTH(X) استفاده کنیم که X مقدار رشته است. اگر X یک مقدار تهی باشد، تابع طول یک مقدار تهی بازگشت میدهد. همچنین میتوان از تابع طول با مقادیر عددی برای دریافت طول مقدار عددی استفاده کرد.
مثال
در مثال زیر تلاش میکنیم با ساختار تابع LENGTH آشنا شویم:
SELECT LENGTH('A string'), LENGTH(NULL), LENGTH(20), LENGTH(20.5);خروجی کوئری فوق به صورت زیر است:

این نتیجه شامل موارد زیر است:
- LENGTH(‘A string’) عدد 8 را بازگشت میدهند که برابر با طول این رشته است.
- LENGTH(NULL) مقدار تهی بازگشت میدهد.
- LENGTH(20) عدد 2 را بازگشت میدهد که برابر با طول رشته 20 است.
- LENGTH(20.5) مقدار 4 بازگشت میدهد، چون نقطه اعشار (.) هم یک کاراکتر محسوب میشود از این رو سه رقم و یک نقطه مجموعاً چهار کاراکتر را تشکیل میدهند.
تغییر کوچکی/بزرگی حروف با تابعهای LOWER و UPPER
LOWER(X) دقیقاً همان رشته ورودی X را بازگشت میدهد، اما این بار همه حروف آن به صورت حروف کوچک انگلیسی هستند. UPPER(X) دقیقاً همان رشته ورودی X را بازگشت میدهد، اما این بار همه حروف آن به صورت حروف بزرگ انگلیسی هستند. در صورتی که یک مقدار تهی به این دو تابع ارسال شود، LOWER و UPPER مقدار تهی بازگشت میدهند.
اگر یک مقدار عددی به این دو تابع ارسال شود، هر دوی آنها دقیقاً همان عدد را بازگشت میدهند.
مثال
SELECT UPPER('a string'), LOWER('A STRING'), UPPER(20), LOWER(20), UPPER(NULL), LOWER(NULL);نتیجه خروجی تابع فوق به صورت زیر است:

در این خروجی موارد زیر را میبینیم:
- UPPER(‘a string’) رشته a string را با حروف بزرگ و به صورت A STRING بازگشت میدهد.
- LOWER(‘A STRING’) رشته A STRING را با حروف کوچک و به صورت a string بازگشت میدهد.
- UPPER(20) و LOWER(20) دقیقاً همان عدد را بازگشت میدهند، چون تأثیری روی اعداد ندارند.
- UPPER(NULL) و LOWER(NULL) مقدار تهی بازگشت میدهند، زیرا مقدار تهی به آنها ارسال شده است.
تابع SUBSTR در SQLite
تابع SUBSTR تعداد خاصی از کاراکترهای یک رشته را بازگشت میدهد که از موقعیت خاصی نیز آغاز میشود. این تابع سه عملوند مانند SUBSTR(X,Y,Z) به شرح زیر دریافت میکند:
- X لفظ رشتهای یا ستون رشتهای است که باید تحلیل شود. امکان ارسال یک لفظ رشتهای (مقدار استاتیک) یا نام یک ستون در این مورد وجود دارد که در این حالت مقادیر از ستون رشتهای خوانده میشوند.
- Y نقطه آغازین انتخاب زیررشته از رشته اصلی است.
- Z تعداد کاراکترهایی است که از رشته اصلی از موقعیت Y به بعد برداشته میشود. این عدد اختیاری است و در صورتی که آن را نادیده بگیرید، SQLite زیررشتهای از موقعیت Y در رشته اصلی تا انتهای آن رشته بازگشت میدهد.
مثال
در کوئری زیر، از تابع SUBSTR برای دریافت 4 کاراکتر از یک رشته استفاده کردهایم که از کاراکتر دوم نام دانشجویان آغاز میشود:
SELECT StudentName, SUBSTR(StudentName, 2, 4), SUBSTR(StudentName, 2)
FROM Students;نتیجه اجرای کوئری فوق به صورت زیر است:
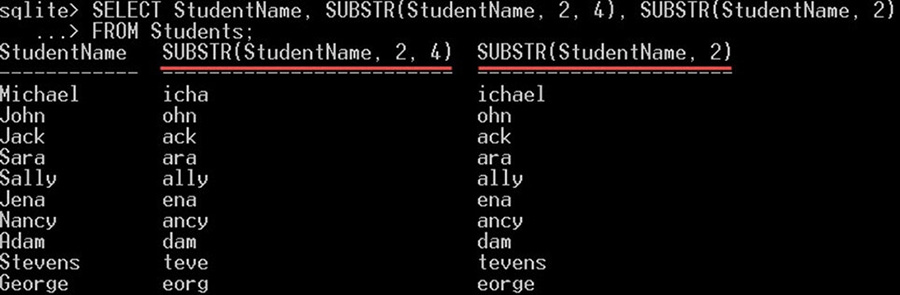
در کوئری فوق SUBSTR(StudentName, 2, 4) یک زیررشته از StudentName را با آغاز از کاراکتر دوم و به طول 4 کاراکتر بازگشت میدهد. اما تابع SUBSTR(StudentName, 2) که در آن طول رشته را ذکر نکردهایم، همه کاراکترهای رشته StudentName را از کاراکتر دوم به بعد بازگشت میدهد.
تغییر دادن بخشهایی از یک رشته با تابع REPLACE
از تابع REPLACE برای جایگزینی بخشهایی از یک رشته استفاده میکنیم. ساختار آن به صورت REPLACE(X, Y, Z) است که در آن X لفظ رشته ورودی یا ستون رشتهای است. Y رشتهای است که باید با رشته Z جایگزین شود. توجه کنید که این تابع همه موارد رشته Y و نه فقط یک مورد خاص را با رشته Z جایگزین میکند.
مثال
در کوئری زیر همه رخدادهای رشته xx ر ا با رشته SQLite جایگزین میکنیم:
SELECT REPLACE('xx is very lightweight, xx is easy to learn', 'xx', 'SQLite');نتیجه اجرای کوئری فوق به صورت زیر است:

چنان که میبینید تابع replace همه رشتههای xx را با رشته SQLite عوض کرده است. به این ترتیب خروجی به صورت زیر در آمده است:
SQLite is very lightweight, SQLite is easy to learn
حذف فواصل خالی با تابع TRIM
تابع TRIM فواصل خالی را از ابتدا و انتهای یک رشته حذف میکند. این تابع فاصلههای موجود میان کلمات داخل رشته را حذف نمیکند و تنها این فاصلهها را ابتدا و انتها پاک میکند.
مثال
در کوئری زیر از تابع TRIM برای حذف فاصلههای خالی از ابتدا و انتهای رشته استفاده کردهایم. توجه کنید که عملگر الحاق (||) برای افزودن نقطهویرگول (;) به انتهای رشته استفاده شده است تا به شما نشان دهیم که فاصلههای خالی کجا قرار دارند:
SELECT TRIM(' SQLite is easy to learn ') || ';';نتیجه اجرای کوئری فوق چنین است:

توجه کنید که فاصلههای خالی از آغاز و پایان رشته حذف شده و در انتها ب ا; جایگزین گشتهاند.
خواندن مقادیر مطلق با تابع ABS
تابع ABS قدر مطلق یک مقدار عددی را بازگشت میدهد. در مطلق یک مقدار عددی، آن عدد بدون علامت مثبت یا منفی است. بنابراین ABS(X) یک مقدار بسته به مقدار ورودی X بازگشت میدهد:
- در صورتی که X یک مقدار عددی باشد، قدر مطلق آن بازگشت مییابد.
- در صورتی که X مقدار تهی باشد، یک مقدار NULL بازگشت مییابد.
- در صورتی که X یک رشته باشد مقدار “0.0” بازگشت مییابد.
مثال
در کوری زیر قدر مطلق یک رشته، یک عدد و یک مقدار تهی را با استفاده از تابع ABS بررسی میکنیم:
SELECT ABS(-2), ABS(+2), ABS('a string'), ABS(null);نتیجه اجرای کوئری فوق به صورت زیر است:

در خروجی فوق موارد زیر را مشاهده میکنیم:
- (ABS(-2 و ABS(+2) هر دو مقدار 2 را بازگشت میدهند، زیرا قدر مطلق هر دو عدد 2- و 2+ عدد 2 است.
- ABS(‘a string’) مقدار “0.0” بازگشت میدهد زیرا یک رشته ارسال شده است و مقدار عددی ندارد.
- ABS(null) مقدار تهی بازگشت میدهد زیرا یک مقدار تهی به آن ارسال شده است.
رند کردن مقادیر با تابع ROUND در SQLite
اعداد اعشاری به اعدادی با ممیز گفته میشود. برای نمونه اعداد 20.5 و 6.85 اعداد اعشاری هستند. بخش چپ اعداد اعشاری به نام جزء صحیح و سمت راست آنها به نام بخش اعشاری خوانده میشود.
اعداد صحیح به اعدادی بدون هر گونه ممیز اعشار گفته میشود. برای مثال اعداد 20 و 8 عدد صحیح هستند.
تابع ROUND(X) مقادیر اعشاری یا ستون X را به جزء صحیح آن عدد تبدیل میکند. جزء صحیح یک عدد در سمت چپ ممیز قرار دارد و همه ارقام سمت راست ممیز با استفاده از این تابع حذف میشوند.
مثال
در کوئری زیر از تابع ROUND با سه گزینه مختلف استفاده کردهایم:
SELECT ROUND(12.4354354), ROUND(12.4354354, 2), ROUND(NULL), ROUND('a string');نتیجه اجرای کوئری فوق به صورت زیر است:
در تصویر فوق موارد زیر را مشاهده میکنیم:
- ROUND(12.4354354) مقدار 12 را بازگشت میدهد، زیرا تعداد ارقام مشخص نشده است. بنابراین SQLite همه بخش اعشاری را حذف کرده است.
- ROUND(12.4354354, 2) مقدار 12.44 را بازگشت میدهد، زیرا 2 رقم برای گرد کردن مشخص شده است و از این رو دو رقم اعشار از عدد حفظ شده و بقیه ارقام حذف شدهاند.
- ROUND(NULL) مقدار تهی بازگشت میدهد، زیرا یک مقدار تهی به این تابع ارسال شده است.ROUND(‘a string’) مقدار “0.0” بازگشت میدهد زیرا یک مقدار رشتهای به آن ارسال شده است.
یافتن نوع دادهای یک عبارت با تابع TYPEOF
اگر بخواهید نوع دادههای یک ستون یا یک مقدار استاتیک را پیدا کنید میتوانید از تابع TYPEOF به این منظور بهره بگیرید. تابع TYPEOF چنان که از نام آن برمیآید، نوع دادههای عبارت X را بازگشت میدهد. این تابع بسته به نوع داده که مقدار تهی، یا عدد real یا متن یا عدد صحیح و غیره باشد، مقداری را بازگشت میدهد.
مثال
در کوئری زیر تابع TYPEOF را با انواع مختلفی از مقادیر لفظی بررسی میکنیم:
SELECT TYPEOF(null), TYPEOF(12), TYPEOF(12.5), TYPEOF('a string');نتیجه اجرای کوئری فوق به صورت زیر است:

نتایج بازگشتی در تصویر فوق به شرح زیر هستند:
- TYPEOF(null) مقدار تهی بازگشت میدهد، زیرا مقدار تهی به آن ارسال شده است.
- TYPEOF(12) عدد صحیح بازگشت میدهد زیرا 12 یک عدد صحیح است.
- TYPEOF(12.5) عدد REAL بازگشت میدهد، زیرا 12.5 یک عدد REAL است.
- TYPEOF(‘a string’) یک متن بازگشت میدهد، زیرا a string یک متن است.
یافتن آخرین رکورد درج شده با تابع LAST_INSERT_ROWID
SQLite یک کلید صحیح (id) برای همه ردیفهای جدول اختصاص میدهد. این عدد برای شناسایی یکتای همه ردیفها مورد استفاده قرار میگیرد. زمانی که یک ردیف جدید را روی جدول INSERT میکنید، SQLite یک «شناسه ردیف» (rowid) به صورت مقدار یکتا به آن انتساب میدهد.
اگر جدول دارای یک «کلید اصلی» (primary key) باشد که صرفاً روی یک ستون اعلان شده باشد و آن ستون از نوع INTEGER باشد، در این صورت از این ستون به عنوان rowed استفاده میشود..
تابع ()LAST_INSERT_ROWID مقدار ROW_ID آخرین ردیف درج شده در جدول در دیتابیس را بازگشت میدهد. توجه کنید که این تابع هیچ عملوندی نمیپذیرد.
مثال
در مثال زیر تابع LAST_INSERT_ROWID() به صورت زیر تعریف میشود:
SELECT LAST_INSERT_ROWID();که خروجی زیر را تولید میکند:
()LAST_INSERT_ROWID مقدار 0 بازگشت میدهد زیرا هیچ ردیفی در هیچ جدولی در اتصال کنونی دیتابیس درج نشده است.
اکنون یک دانشجوی جدید درج کرده و تابع ()LAST_INSERT_ROWID را مجدد اجرا میکنیم:
INSERT INTO Students VALUES(11, 'guru', 1, '1998-10-12');
SELECT LAST_INSERT_ROWID();کوئری فوق نتیجه زیر را به دست میدهد:

پس از درج یک دانشجوی جدید با شناسه 11 تابع ()LAST_INSERT_ROWID شناسه آخرین ردیف درج شده را که برابر با 11 است بازگشت میدهد.
دریافت نسخه کتابخانه SQLite
برای دریافت نسخه کتابخانه SQlite باید تابع ()SQLITE_VERSION را فراخوانی کنیم.
مثال
با اجرای دستور زیر نسخه کتابخانه SQLite خود را به دست میآوریم:
SELECT SQLITE_VERSION();نتیجه اجرای این کوئری به صورت زیر است:
چنان که میبینید تابع SQLITE_VERSION() عدد 3.9.2 را بازگشت داده است که برابر با نسخه SQLite مورد استفاده ما است.
ایجاد و تجمیع تابعهای تعریف شده کاربر
با این که SQLite تابعهای زیادی برای کار با دادهها دارد، اما شاید این مقدار برای برخی افراد کافی نباشد. این افراد ممکن است نیاز به افزودن برخی تابعهای سفارشی برای رفع نیازهای خاص خود داشته باشند. SQLite از ایجاد تابعهای تعریف شده از سوی کاربر پشتیبانی نمیکند. برخلاف دیگر سیستمهای مدیریت پایگاه داده در SQLite امکان نوشتن مستقیم تابع وجود ندارد.
با این حال شما میتوانید با استفاده از زبانهایی مانند C ،C# ،PHP یا ++C توابعی را بنویسید و به تابعهای هسته اصلی SQLite در کتابخانه SQlite اضافه کنید. به این منظور باید از تابع sqlite3_create_function کمک بگیرید. به این ترتیب میتوانید از این تابعهای سفارشی در دیتابیس خود بارها و بارها استفاده کنید.
مثال
در مثال زیر ما یک تابع تعریف شده کاربر با استفاده از زبان برنامهنویسی #C ایجاد کرده و به تابعهای SQLite اضافه میکنیم:
[SQLiteFunction(Name = "DoubleValue", Arguments = 1, FuncType = FunctionType.Scalar)]
public class DoubleValue: SQLiteFunction
{
public override object Invoke(object[] args)
{
return args[0] * 2;
}
}این قطعه کد به زبان #C نوشته شده است و یک تابع #C ایجاد میکند. نام این تابع DoubleValue است و یک پارامتر میگیرد و مقدار آن را در 2 ضرب کرده و بازگشت میدهد.
توجه کنید که #C به صورت خودکار این تابع را به SQLite اضافه میکند. تنها کاری که باید بکنید این است که کد را کامپایل کرده و اجرا نمایید. سپس #C این تابع را با همان نام به لیست تابعهای SQLite اضافه خواهد کرد و میتوانید در ادامه از آن در این سیستم مدیریت دیتابیس بهره بگیرید.
به همین ترتیب میتوانید تابعهایی با استفاده از زبانهایی مانند C#, C, PHP یا ++C ایجاد کنید. همچنین میتوانید تابعهای تعریف شده کاربر را تجمیع نمایید. این روش برای بسط دادن تابعهای تجمیع داخلی SQLite و استفاده از آنها برای ایجاد تابعهای تجمیع سفارشی تعبیه شده است.
SQLite مجموعه جامعی از تابعهای داخلی دارد که موجب میشود کار با جدولها و ستونهای پایگاه داده آسانتر شود. شما میتوانید از این تابعها روی ستونها و همچنین مقادیر لفظی درون عبارت در کوئریهای SQLite استفاده کنید.
سخن پایانی
به این ترتیب به پایان این مقاله جامع در خصوص معرفی و آموزش دیتابیس SQLite میرسیم. SQite یک کتابخانه به زبان C است که یک موتور دیتابیس SQL به صورت کوچک، مستقل، با پایداری بالا و امکانات فراوان پیادهسازی میکند. SQLite پراستفادهترین موتور دیتابیس در سراسر دنیا است.
این سیستم مدیریت پایگاه داده در گوشیهای موبایل، و اغلب رایانهها حضور دارد و به صورت بستهبندی شده درون بسیاری از اپلیکیشنها که به طور روزمره استفاده میکنیم، عرضه شده است. کدبیس این موتور دیتابیس به صورت رایگان و متن-باز عرضه شده است. SQLite برخلاف اغلب انواع دیگر سیستمهای مدیریت پایگاه داده سرور اختصاصی ندارد و دادهها را مستقیماً روی دیسک خوانده و مینویسد. یادگیری این سیستم مدیریت دیتابیس برای اغلب توسعهدهندگان در هر زمینه و رشتهای اگر نه یک ضرورت، دستکم یک مزیت بزرگ محسوب میشود.